业界 | 百度提出神经TTS技术Deep Voice 2:支持多说话人的文本转语音
选自Baidu Blog
机器之心编译
参与:吴攀、蒋思源
今年 2 月份,百度提出了一种完全由深度神经网络构建的高质量文本转语音(TTS)系统 Deep Voice,参见机器之心报道《百度提出 Deep Voice:实时的神经语音合成系统》。近日,百度对这一系统进行了更新,提出了 Deep Voice 2,其可以使用单个模型生成不同的声音。百度在其研究博客上对这一研究进行了简单的介绍,机器之心对该博客文章和论文部分内容进行了编译介绍。有关文本转语音的更多研究,可扩展阅读机器之心文章《语音合成到了跳变点?深度神经网络变革 TTS 最新研究汇总》。
在今年 2 月,百度硅谷人工智能实验室发布了 Deep Voice 1,该系统是一个完全用深度神经网络构建的人类语音合成系统。Deep Voice 1 与其他神经文本转语音(TTS)系统不同,它不仅能实时运行,同时还可以足够快速地合成音频,因此 Deep Voice 1 可以应用于媒体和会话接口等交互性应用。通过训练能由大量数据和简单特征(而不是人工定制的数据)学习的深度神经网络,我们创建了一个极其灵活的高质量实时音频合成系统。
今天,我们很高兴发布作为 Deep Voice 下一代的系统——Deep Voice 2。在短短的三个月里,我们已经将系统从 20 小时的语音(speech)、单一声音(voice)扩展到数百小时的语音与数百种声音。Deep Voice 2 能学习数百种声音并完美地模仿它们。与传统系统不同,Deep Voice 2 不需要来自单一说话者数十小时的音频,其只需要每个说话者不到半个小时的数据就能学会数百种独特的声音,同时还能实现非常高的质量。
Deep Voice 2 通过寻找不同声音之间的共享特质(shared qualities)而学习生成语音。具体而言,每一个语音对应着单个向量,该向量大约有 50 个元素且总结了如何生成能模拟目标说话者的声音。与以前所有的 TTS 系统不同,Deep Voice 2 可以从头开始学习这些特质,无需任何标记语音特征的引导。
以下是来自我们系统的一组样本,其经过大约 100 个说话者数据的训练。每一个说话者都有其自己的说话节奏、口音、语调和发音习惯等,但我们的系统几乎都能完全模仿出来。
(注:由于微信的规则限制,机器之心无法在本文中直接呈现上述音频样本,感兴趣的读者可访问原文试听。原文地址参见文末。)
论文:Deep Voice 2:多说话人神经文本转语音(Deep Voice 2: Multi-Speaker Neural Text-to-Speech)

我们介绍了一种用于增强神经文本转语音(TTS)的技术,该技术使用了低维可训练的说话人嵌入(embedding)来从单个模型中生成不同的声音。首先,我们给出了超越两个用于单说话人神经 TTS 的当前最佳方法(Deep Voice 1 和 Tacotron)的提升。我们介绍了 Deep Voice 2,其基于与 Deep Voice 1 相似的流程,但却使用了更高性能的构建模块,并在 Deep Voice 1 的基础上表现出了显著的音频质量提升。我们通过引入一个后处理神经声码器(post-processing neural vocoder)而改进了 Tacotron,并且表现出了显著的音频质量提升。然后我们表明我们的技术可以在 Deep Voice 2 和 Tacotron 中用于多说话人语音合成,并在两个多说话人 TTS 数据集上进行了测试。我们表明单个神经 TTS 系统就能在每个说话人不到半小时数据的前提下学会数百种不同的声音,同时还能实现高质量的音频合成并近乎完美地保留说话人的身份。
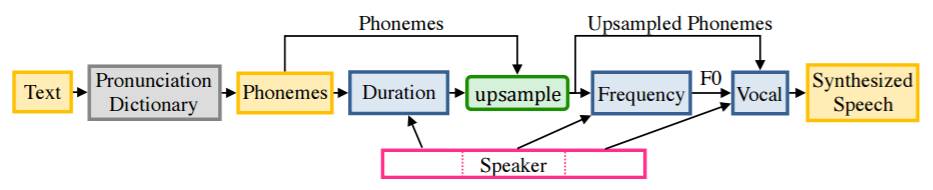
图 1:推理系统框图:首先是文本-音素词典转换,其次是预测音素持续时间,第三是上采样和生成 F0,最后将 F0 和音素馈送到声音模型(vocal model)
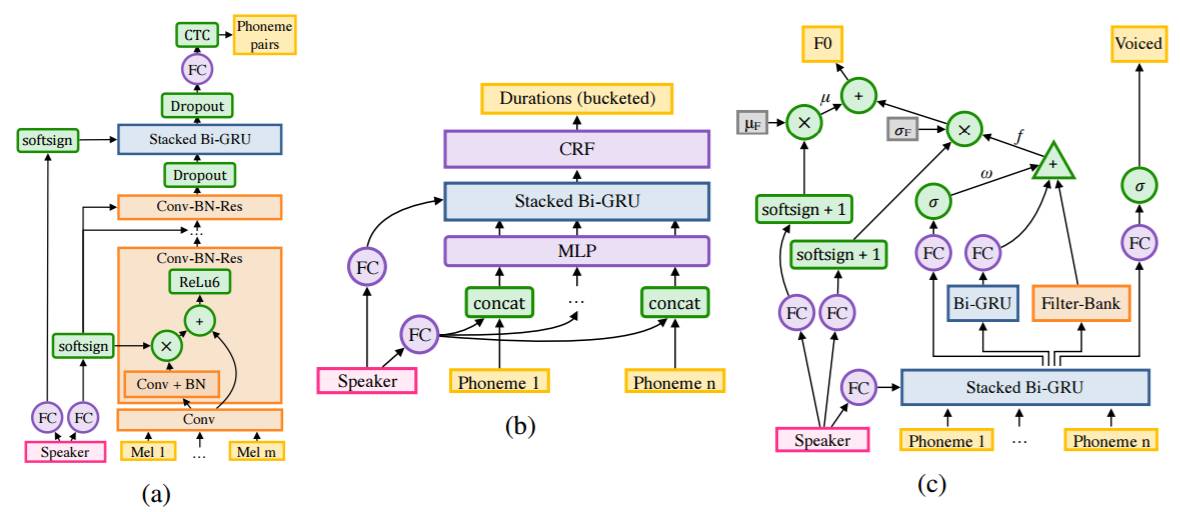
图 2:用于多说话人的架构。(a) 分割模型 (b) 持续时间模型 (c) 频率模型
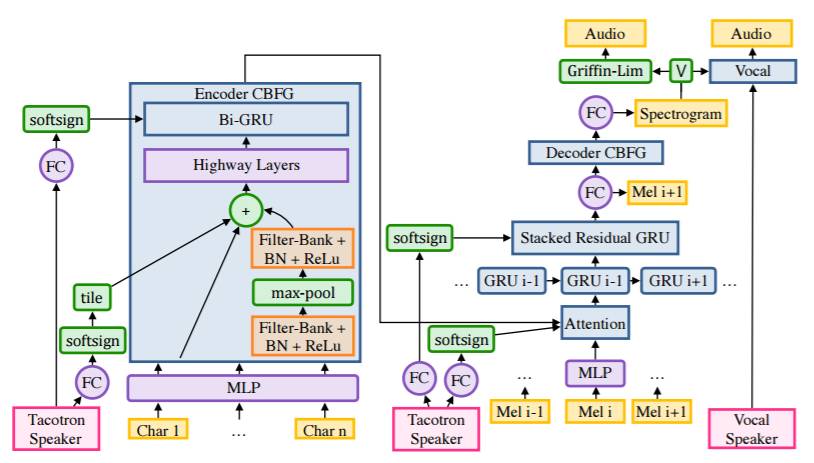
图 3:Tacotron,在 Encoder CBHG 模块中带有说话人调节(speaker conditioning),还有带有两种将频谱转换成音频的方法:Griffin-Lim 或我们的调节过说话人的 Vocal 模型
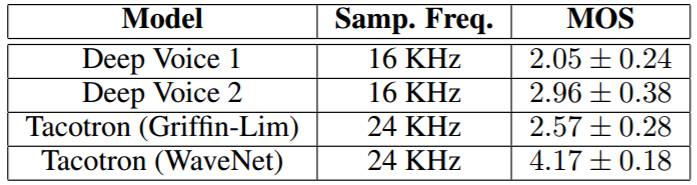
表 1:Deep Voice 1、Deep Voice 2 和 Tacotron 的平均意见分数(MOS)评估,使用了 95% 的置信区间。使用了 crowdMOS 工具包,来自这些模型的批量样本在 Mechanical Turk 上被呈现给评估者。因为这些批量样本包含来自所有模型的样本,所以该实验是这些模型之间的自然比较。

表 2:所有多说话人模型之间的 MOS 和分类准确度比较。为了得到 MOS,我们使用了 crowdMOS 工具包,细节如表 1 所示。我们还给出了在样本上的说话人鉴别模型(详情参见附录 D)的分类准确度,表明其合成的声音的区分度和真实音频一样。
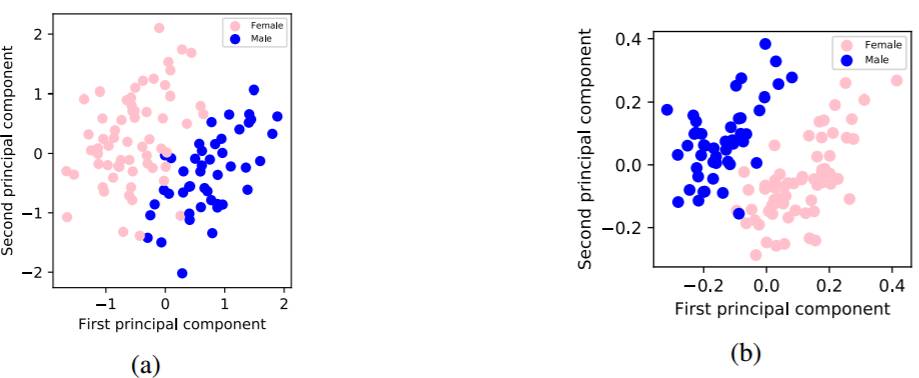
图 4:学习到的说话人嵌入的主成分,这是在 VCTK 数据集上学习到,分别来自 (a) 80 层的声音模型(vocal model)和 (b) 字符到频谱模型。详见附录 C.3。
原文链接:http://research.baidu.com/deep-voice-2-multi-speaker-neural-text-speech/
点击阅读原文,查看机器之心 GMIS 2017 大会官网↓↓↓


这篇文章还没有评论