教程 | 初学文本分析:用Python和scikit-learn实现垃圾邮件过滤器
选自kdnuggets
机器之心编译
参与:王宇欣、吴攀
本文介绍了如何通过 Python 和 scikit-learn 实现垃圾邮件过滤的。对比和分析了两个分类器的结果:多项式朴素贝叶斯和支持向量机。
文本挖掘(text mining,从文本中导出信息)是一个广泛的领域,因为不断产生的巨量文本数据而已经得到了普及。情绪分析、文档分类、主题分类、文本概括、机器翻译等许多任务的自动化都已经通过机器学习得到了实现。
垃圾邮件过滤(spam filtering)是文档分类任务的入门级示例,其涉及了将电子邮件分为垃圾邮件或非垃圾邮件(也称为 ham)。你的 Gmail 账户的垃圾邮箱就是最好的例子。那么让我们在公开的邮件语料库上构建垃圾邮件过滤器吧。我已经从 Ling-spam 语料库(http://www.aueb.gr/users/ion/data/lingspam_public.tar.gz)上提取了同等数量的垃圾邮件和非垃圾邮件。我们从这里下载将要对其操作的提取出来的子集:https://www.dropbox.com/s/yjiplngoa430rid/
我们将通过以下步骤构建此应用程序:
1. 准备文本数据
2. 创建词典
3. 特征提取过程
4. 训练分类器
此外,我们将在该子集中的测试集上测试我们的结果。
1、 准备文本数据
这里使用的数据集被分为训练集和测试集,分别包含了 702 封邮件和 260 封邮件,其中垃圾邮件和 ham 邮件的数量相等。垃圾邮件的文件名中包含了 spmsg,所以很容易识别。
在任何一个文本挖掘问题中,文本清理(text cleaning)是我们从文档中删除那些可能对我们想要提取的信息无用的文字的第一步。电子邮件可能包含了大量对垃圾邮件检测无用的字符,如标点符号、停止词、数字等。Ling-spam 语料库中的邮件已经通过以下方式进行了预处理:
a) 移除停止词—像「and」、「the」、「of」之类的停止词在所有的英语句子当中都非常常见,在判定是否为垃圾邮件时没有多少作用,所以这些词已经从电子邮件中删除。
b) 词形还原(lemmatization)—这是将一个单词的不同变化形式分组在一起的过程,以便其可被视为单个项进行分析。例如,「include」、「includes」和「included」将全部用「include」表示。在词形还原中,句子的语境也会得到保留,而词干提取(stemming)则不会。(词干提取是文本挖掘中的另一个术语,其不会考虑句意)。
我们还需要从邮件文档中删除非文字信息,比如标点符号或者特殊字符。有几种方法可以做到这一点。这里,我们将在创建词典后删除这样的词,这非常方便,因为当你有了一个词典时你只需要删除每个这样的单词一次。欢呼吧!!到现在为止,你不需要做任何事情。
2、创建词典
数据集中的示例邮件如下所示:
hi , ' m work phonetics project modern irish ' m hard source . anyone recommend book article english ? ' , specifically interest palatal ( slender ) consonant , work helpful too . thank ! laurel sutton ( sutton @ garnet . berkeley . edu
可以看出,邮件第一行是主题(subject),第三行包含了邮件的正文。我们只会对其内容执行文本分析以检测垃圾邮件。作为第一步,我们需要创建一个词及其频率的词典。对于此任务,我们使用了 700 封邮件作为训练集。这个 Python 函数可为你创建这个词典。
def make_Dictionary(train_dir):
emails = [os.path.join(train_dir,f) for f in os.listdir(train_dir)]
all_words = []
for mail in emails:
with open(mail) as m:
for i,line in enumerate(m):
if i == 2: #Body of email is only 3rd line of text file
words = line.split()
all_words += words
dictionary = Counter(all_words)
# Paste code for non-word removal here(code snippet is given below)
return dictionary
一旦词典被创建,我们可以添加下面几行代码到上面的函数以删除移除非词(如第 1 步所示)。我也删除了词典中不合理的单个字符,这些字符在这里是不相关的。别忘了在函数 def make_Dictionary(train_dir) 中插入以下代码。
list_to_remove = dictionary.keys()
for item in list_to_remove:
if item.isalpha() == False:
del dictionary[item]
elif len(item) == 1:
del dictionary[item]
dictionary = dictionary.most_common(3000)
可以通过命令 print dictionary 显示词典。你也许会发现一些不合理的单词数很多,但是别担心,这只是一个词典并且稍后你可以改进它。如果你是按照这篇文章说的那样操作的并且使用了我提供的数据集,那么请确保你的词典中包含以下最常用的单词的条目。这里,我已经选择了 3000 个词典中最常用的词。
[('order', 1414), ('address', 1293), ('report', 1216), ('mail', 1127), ('send', 1079), ('language', 1072), ('email', 1051), ('program', 1001), ('our', 987), ('list', 935), ('one', 917), ('name', 878), ('receive', 826), ('money', 788), ('free', 762)
3、特征提取过程
一旦词典准备就绪,我们可以为训练集的每封邮件提取 3000 维的词计数向量(word count vector,这里是我们的特征)。每个词计数向量包含了训练文件中的 3000 个单词的频率。当然,你现在可能已经猜到了它们大部分是 0。让我们举个例子。假设我们的词典中有 500 个词。每个词计数向量包含训练文件中 500 个字典词的频率。假设训练文件中的文本是「Get the work done, work done」,那么它将被编码为 [0,0,0,0,0,... .0,0,2,0,0,0,......,0,0,1,0,0,... 0,0,1,0,0,... 2,0,0,0,0,0]。在这个 500 长度的词计数向量中,只有的第 296、359、415、495 位有词的计数值,其余位置都是零。
下面的 Python 代码将生成一个特征向量矩阵,其中行表示训练集的 700 个文件,列表示词典的 3000 个词。索引「ij」处的值将是第 i 个文件中词典的第 j 个词的出现次数。
def extract_features(mail_dir):
files = [os.path.join(mail_dir,fi) for fi in os.listdir(mail_dir)]
features_matrix = np.zeros((len(files),3000))
docID = 0;
for fil in files:
with open(fil) as fi:
for i,line in enumerate(fi):
if i == 2:
words = line.split()
for word in words:
wordID = 0
for i,d in enumerate(dictionary):
if d[0] == word:
wordID = i
features_matrix[docID,wordID] = words.count(word)
docID = docID + 1
return features_matrix
4、训练分类器
这里,我将使用 scikit-learn 机器学习库(http://scikit-learn.org/stable/)训练分类器。这是一个开源 Python 机器学习库,其被捆绑在第三方分布 anaconda(https://www.continuum.io/downloads)中,也可以按这个教程单独安装使用:http://scikit-learn.org/stable/install.html。一旦安装,我们只需要将其导入到我们的程序中即可。
我已经训练了两个模型,即朴素贝叶斯分类器(Naive Bayes classifier)和支持向量机(SVM)。对于文档分类问题,朴素贝叶斯分类器是一种常规的并且非常流行的方法。它是一个基于贝叶斯定理的监督概率分类器,其假设每对特征之间是独立的。支持向量机是监督式的二元分类器,在你拥有更多的特征时它非常有效。支持向量机(SVM)的目标是将训练数据中的一些子集从被称为支持向量(support vector,分离超平面的边界)的剩余部分分离。预测测试数据类型的支持向量机模型的决策函数基于支持向量并且利用了核技巧(kernel trick)。
一旦分类器训练完毕,我们可以在测试集上检查模型的表现。我们提取了测试集中的每一封邮件的词计数向量,并使用训练后的朴素贝叶斯(NB)分类器和支持向量机模型预测其类别(ham 邮件或垃圾邮件)。以下是垃圾邮件过滤应用程序的完全代码。你必须包含我们在之前的步骤 2 和步骤 3 定义的两个函数。
import os
import numpy as np
from collections import Counter
from sklearn.naive_bayes import MultinomialNB, GaussianNB, BernoulliNB
from sklearn.svm import SVC, NuSVC, LinearSVC
# Create a dictionary of words with its frequency
train_dir = 'train-mails'
dictionary = make_Dictionary(train_dir)
# Prepare feature vectors per training mail and its labels
train_labels = np.zeros(702)
train_labels[351:701] = 1
train_matrix = extract_features(train_dir)
# Training SVM and Naive bayes classifier
model1 = MultinomialNB()
model2 = LinearSVC()
model1.fit(train_matrix,train_labels)
model2.fit(train_matrix,train_labels)
# Test the unseen mails for Spam
test_dir = 'test-mails'
test_matrix = extract_features(test_dir)
test_labels = np.zeros(260)
test_labels[130:260] = 1
result1 = model1.predict(test_matrix)
result2 = model2.predict(test_matrix)
print confusion_matrix(test_labels,result1)
print confusion_matrix(test_labels,result2)
测试表现水平
测试集包含 130 封垃圾邮件 和 130 封非垃圾邮件。如果你已经走到了这一步,你将会发现以下结果。我已经展示出了对这两个模型的训练集的混淆矩阵(confusion matrix)。对角元素表示正确识别(也叫真识别)的邮件,其中非对角元素表示邮件的错误分类(假识别)。
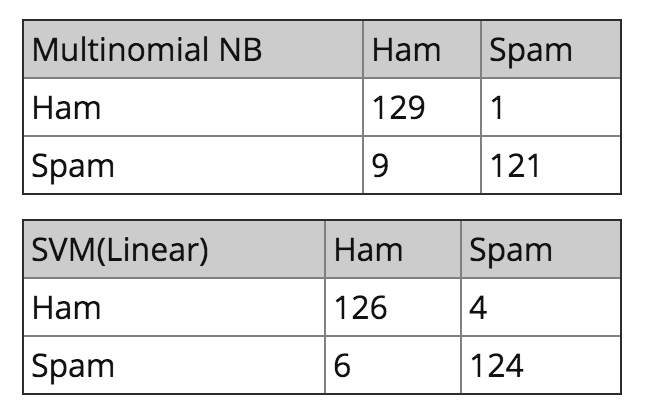
除了 SVM 具有稍微平衡的假识别之外,这两个模型在测试集上具有相似的表现。我必须提醒你,测试数据既没有在创建词典使用,也没有用在训练集中。
你的任务
下载 Euron-spam 语料库(http://www.aueb.gr/users/ion/data/enron-spam/)的预处理表格。该语料库在 6 个目录中包含了 33716 封邮件,其中包含「ham」和「spam」文件夹。非垃圾邮件和垃圾邮件的总数分别为 16545 和 17171。
遵循本文章中描述的相同步骤,并检查它如何执行支持向量机和多项式朴素贝叶斯模型。由于该语料库的目录结构不同于博客文章中使用的 ling-spam 子集的目录结构,因此你可能需要重新对其组织或在 def make_Dictionary(dir) 和 def extract_features(dir) 函数中进行修改。
我将 Euron-spam 语料库以 60:40 的比例分成训练集和测试集。执行本博客的相同步骤后,我在 13487 封测试集邮件中得到以下结果。我们可以看到,在正确检测垃圾电子邮件方面的表现,支持向量机(SVM)略优于朴素贝叶斯分类器。
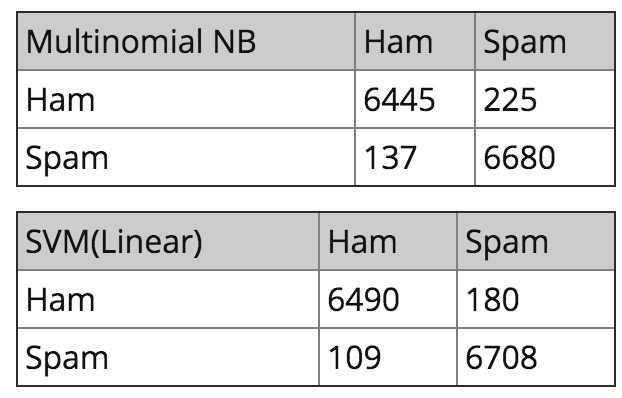
最后的感想
我试图保持教程的简洁性。希望对文本分析感兴趣的初学者可以从这个应用程序开始。
你可能会思考朴素贝叶斯和支持向量机(SVM)背后的数学技术。支持向量机(SVM)在数学上是较为复杂的模型,但朴素贝叶斯相对容易理解。我鼓励你从在线资源中学习这些模型。除此之外,你可以进行很多实验以便发现各种参数的效果,比如
-
训练数据的数量
-
词典的大小
-
不同的机器学习技术,比如 GaussianNB、BernoulliNB、SVC)
-
对支持向量机模型参数进行调优
-
通过消除不重要的词(可以手动)以改进词典
-
一些其它的特征(可搜索 td-idf 了解)
你可以从 GitHub 获得这两种语料库的完整 Python 实现:https://github.com/abhijeet3922/Mail-Spam-Filtering。
原文链接:http://www.kdnuggets.com/2017/03/email-spam-filtering-an-implementation-with-python-and-scikit-learn.html
点击阅读原文,报名参与机器之心 GMIS 2017 ↓↓↓


这篇文章还没有评论