资源 | Facebook开源人工智能框架ParlAI:可轻松训练评估对话模型
选自GitHub
机器之心编译
参与:吴攀、晏奇
Facebook 近日在 GitHub 上开源了一个可用于在多种开放可用的对话数据集上训练和评估人工智能模型的框架 ParlAI,机器之心在本文中对这一项目的 README.md 内容进行了编译介绍。项目地址如下:
-
官网地址:http://parl.ai
-
GitHub:https://github.com/facebookresearch/ParlAI

ParlAI(读音为 par-lay)是一个用于对话人工智能研究的框架,是用 Python 实现的。该框架的目标是为研究者提供:
-
一个用于训练和测试对话模型的统一框架
-
一次性在许多数据集上进行多任务训练
-
无缝集成 Amazon Mechanical Turk,以便数据收集和人工评估
这第一个版本支持超过 20 种任务,也囊括了许多流行的数据集,比如 SQuAD、bAbI tasks、MCTest、WikiQA、WebQuestions、SimpleQuestions、WikiMovies、QACNN & QADailyMail、CBT、BookTest、bAbI Dialog tasks、Ubuntu Dialog、OpenSubtitles、Cornell Movie 和 VQA-COCO2014。
还包括使用 PyTorch 和 Lua Torch 训练神经模型的示例,其包含了在 GPU 上的批训练或在 CPU 上的 hogwild 训练。另外使用 Theano 或 TensorFlow 也是很直接的。
我们的目标是让那些在它们之上训练的任务和智能体能够以一种基于社区的方式成长。
这个版本还是早期的 Beta 版,使用过程中可能会有一些冒险,或遇到一些难题。
目标
用于评估模型的统一框架
-
可按需下载任务/数据集,且为它们提供了同样简单的接口
-
统一的数据集输入和评估框架/标准
-
agents/ 目录鼓励研究者提交他们的训练代码,以便在该 repo 中分享
-
协助重现
最终目标是实现通用的对话,包括许多不同的技能
-
无缝地组合模拟的和真实的语言任务
-
鼓励多任务模型的开发和评估
-
有助于减少模型在特定数据集上的过拟合
最终目标是实现与人类的真实对话
-
通过 Mechanical Turk,在与人类的实时对话上训练和评估
-
只需简单的设置,就可以连接 Mechanical Turk 上的人类与你的对话代理
-
允许比较不同研究组的 Turk 实验
能够引导一个可与人类交互的对话模型的数据集配置
-
激励构建将进入本 repo 的新数据集
特性
-
所有的数据集都像自然对话:单一格式/API
-
既有固定数据集(会话日志),也有交互式任务(在线/RL)
-
既有真实任务,也有模拟任务
-
支持其它媒体,比如 VQA 中的视觉
-
可以使用 Mechanical Turk 来运行/收集数据/评估
-
Python 框架
-
PyTorch 的训练示例
-
可使用 zmq 与其它非 Python 的工具箱对话,给出了 Lua Torch 的示例
-
支持模型的 hogwild 训练和批训练
基本示例
从「1k training examples」bAbI 任务的任务 1 中展示 10 个随机样本:
python examples/display_data.py -t babi:task1k:1
同时在 bAbI 任务的多任务与 SQuAD 数据集上展示 100 个随机样本:
python examples/display_data.py -t babi:task1k:1,squad -n 100
在 Movies Subreddit 数据集的验证集上评估 IR 基线模型:
python examples/eval_model.py -m ir_baseline -t "#moviedd-reddit" -dt valid
给出该 IR 基线模型的预测:
python examples/display_model.py -m ir_baseline -t "#moviedd-reddit" -dt valid
在「10k training examples」bAbI 任务 1 上训练一个简单的基于 CPU 的记忆网络,其使用了 Hogwild(需要 zmq 和 Lua Torch),有 8 个线程(Python 进程):
python examples/memnn_luatorch_cpu/full_task_train.py -t babi:task10k:1 -n 8
在 SQuAD 数据集上训练一个「注意 LSTM」模型,其中批大小为 32(PyTorch 和 regex)
python examples/drqa/train.py -t squad -b 32
要求
ParlAI 目前支持 Python3。
核心模组的依赖内容参见 requirement.txt。其中部分模型(在 parlai/agents 中)有进一步要求,比如需要 PyTorch 或 Lua Torch——所有这些模组的要求都可以参见 requirements_ext.txt 这个文档。
安装 ParlAI
首先,复制该 repository,然后进入复制的目录。
链接安装:运行 python setup.py develop 来将复制的目录链接到你的 site-packages。如果你打算根据你的运行修改任何的 parlai 代码或者提交一个 pull request,特别是如果你想在 repository 上添加另外的任务的话,那么我们推荐上述安装过程。所有需要的数据都将被下载到 ./data,而且,如果要求任何模型的文件(目前仅是 memnn 模型),它们都将被下载到 ./downloads。
复制后的安装内容(仅将 parlai 用作一个依赖项):运行 python setup.py install 来将内容复制到你的 site-packages 文件夹。所有数据都会被默认下载到 python 的 site-packages 文件夹中(你可以通过命令行来改写路径),不过一旦对代码作出了任何改动,你都需要重新运行一次安装。如果你仅想将 parlai 作为一个依赖项使用(比如用于访问任务或核心代码),那么目前这样就可以了。但是如果你想要清除下载的数据,那么删除 site-packages/parlai 中的 data 和 downloads 文件夹(如果可以的话)。
Worlds, agents 和 teachers
ParlAI 中的主要概念(类):
-
world——它定义了环境(它可以非常简单,可以仅两个代理相互对话)。
-
agent——这是世界里的一个代理,比如一个学习器。(存在很多学习器。)
-
teacher——这是一种可以和学习者对话的代理,它用于实现前面提到的任务。
在定义完 ParlAI 中的 world 和 agent 之后,一个主 loop 可被用来训练、测试或显示,它叫做 world.parley() 函数。我们在左边的面板中给出了个实例的主要骨架,parley() 函数真实的代码写在右侧面板。

Actions 和 Observations
所有的 agent(包括 teacher)都以简单的格式互相对话——observation/action 对象(这是一个 python 字典)。这被用于传递 agent 之间的文本、标签和奖励。这和当在对话(行动)或听(观察)时是同类对象,但是不同视角(在这些字段中有不同的值)。这些领域如下所述:
尽管'text'(文本)领域将几乎可能在全部交流(exchange)中被使用,但是技术上来说,基于你的数据集,这些领域中的每个都是可选的。
对于一个固定的监督式学习数据集(比如 bAbI)来说,一个典型的从数据集进行交流(exchange)例子可以像如下这样(该测试集不包含标签):
Teacher: {
'text': 'Sam went to the kitchennPat gave Sam the milknWhere is the milk?',
'labels': ['kitchen'],
'label_candidates': ['hallway', 'kitchen', 'bathroom'],
'episode_done': False
}
Student: {
'text': 'hallway'
}
Teacher: {
'text': 'Sam went to the hallwaynPat went to the bathroomnWhere is the milk?',
'labels': ['hallway'],
'label_candidates': ['hallway', 'kitchen', 'bathroom'],
'episode_done': True
}
Student: {
'text': 'hallway'
}
Teacher: {
... # starts next episode
}...
代码
代码被设置进了几个主要目录:
-
core:它包含了框架的首要代码。
-
agents:包含了可以凭不同任务交互的代理(比如:机器学习模型)。
-
example:包含了不同循环的一些基本样例(构建词典、训练/评价、显示数据)。
-
tasks:包含了可来自于 ParlAI 的不同任务的代码。
-
mturk:包含了设置 Mechanical Turk 的代码和作为样例的 MTurk 任务。
下面我们会更具体地说明每个目录,我们根据依赖项(dependency)来组织行文。
Core 库
core 库包含了如下文件:
-
agent.py:这个文件包含了一些可被你自己模型延展的基本 agent。
-
Agent:这是所有 agent 的基本类,实现了 act() 方法,该方法接受一个观察表(table)并且返回一个作为回复的表。
-
Teacher:它是 Agent 的子代,也实现了针对返回量度(returning metric)的报告方法。任务实现了 Teacher 这个类。
-
MultiTaskTeacher:它创造了一个基于「任务字符串」的 teacher 集,该集可以传递给 Teacher。在其中它创建了多个 teacher 并且在它们之间交替轮换。
-
create_task_teacher:它从一段给定的任务字符串中实例化了一个 teacher(比如「babi:task:1」或「squad」)。
-
build_data.py:用于设置任务数据的基本功能。如果你的文件系统需要不同的功能,你可以覆盖它。
-
dialog_teacher.py:包含了用于和固定交谈(chat)日志进行对话(dialog)的一个基本 teacher 类,同时它也包含了一个用于储存数据的数据类(data class)。
-
dict.py:包含了从观察中构建一般 NLP 风格字典的代码。
-
DictionaryAgent:在一个字典中跟踪索引和词频的 agent,可以将一个句子解析成它字典或 back 中的指数(indice)。
-
fbdialog_teacher.py:包含了一个 teacher 类,该类实现了一个 setup_data 函数,这个函数用 Facebook 的 Dialog 数据格式来解析数据。
-
metrics.py:计算对话的评价量度,比如对排名的量度等。
-
params.py:用 argparse 来为 ParlAI 解释命令行 argument。
-
thread_utils.py:用于 Hogwild 多线程(多重处理)的工具类/函数。
-
SharedTable:提供一个锁保护、记忆分享、类字典的用于追踪度量的的界面。
-
worlds.py:包含了一套用于内部开展任务的基本 world。
-
World:所有 world 的基本类,实现了 parley,shutdown,__enter__,和__exit__。
-
DialogPartnerWorld:用于双 agent 回合交流的默认 world。
-
MultiAgentDialogWorld:用于两到多个 agent 的循环(round-robin)回合 agent 交流。
-
HogwildWorld:当使用多线程(多重处理)时。这是用于设置一个对每个线程而言分别独立的 world 的默认 world。
Agents 目录
agents 目录包含了已被认可进入 ParlAI 框架用于分享的 agent。目前有这些可用的目录:
-
drqa:这是一个很周全的 LSTM 模型,它叫「DrQA」(问答博士,论文地址:https://arxiv.org/abs/1704.00051)。它用 PyTorch 框架实现,在 SQuAD 数据集上,它得到的结果相比其它模型更具竞争力。
-
memnn:它是在 Lua Torch 中用于端到端记忆网络的代码。
-
remote_agent:连接 ZMQ 的任意 agent 的基本类(memnn_luatorch_cpu 就使用这个)。
-
ir_baseline:简单的信息检索基准(baseline),它用 TFIDF-权重匹配为候选者的反馈评分。
-
repeat_label:仅重复(repeating)发送给它的所有数据的基本类(如连接(piping)到一个文件、调试)。
实例
这个目录包含了部分基本循环的具体例子。
-
base_train.py:一个非常简单的例子,展示了一个使用默认 Agent 亲本类的训练/验证循环的轮廓。
-
display_data.py:使用 agent.repeat_label 来显示来命令行给出的特定任务的数据。
-
display_model.py:显示对一个给定模型在命令行给出的特定任务之上的预测。
-
eval_model.py:使用命名后的 agent 来计算一个命令行给出的特定任务的评价量度(evaluation metric)数据。
-
build_dict.py:使用 core.dict.DictionaryAgent 建立一个来自命令行给出的特定任务的 dictionary。
-
memnn_luatorch_cpu:展示了一些在几个数据集上训练端到端记忆网络的例子。
-
drqa:展示了如何在 SQuAD 训练集上训练一个周全的 LSTM「DrQA」模型(论文地址:https://arxiv.org/abs/1704.00051)。
任务
这个第一版本支持超过 20 种任务,包括 SQuAD、bAbI tasks、MCTest、WikiQA、WebQuestions、SimpleQuestions、WikiMovies、QACNN、QADailyMail、CBT、BookTest、bAbI Dialog tasks、Ubuntu、OpenSubtitles、Cornell Movie 和 VQA-COCO2014 等流行的数据集。
我们的第一版包含以下数据集,见下图左栏;获取它们也非常简单,只需在命令行的选项中指定对应任务的名称即可,如右栏的数据集展示实用程序所示。查阅当前完整任务列表请访问:https://github.com/facebookresearch/ParlAI/blob/master/parlai/tasks/task_list.py

在 ParlAI 中选择一个任务非常简单,只需要在命令行中指定它既可,如上图(右)所示。如果该数据集之前没有被使用过,那 ParlAI 将会自动下载它。因为在 ParlAI 中,所有的数据集的处理方式都是一样的(使用单个对话 API),所以原则上一个对话代理可以在这些数据集之间切换训练和测试。还不止于此,你可以简单地通过提供一个逗号分隔的列表来一次性指定许多任务(多任务),比如命令「-t babi,squad」可以使用这两个数据集,甚至还可以使用「-t #qa」命令一次性指定所有的 QA 数据集或使用「-t #all」一次性指定 ParlAI 中的每一个任务。我们的目标是使其可以轻松地创建和评估非常丰富的对话模型。
每个任务文件夹包含:
-
build.py 文件,用于设置任务的数据(下载数据等,仅在第一次请求时完成,如果某个任务从未被使用,那么就不会下载它)。
-
agents.py 文件,包含了默认的或特定的教师(teacher)类别,可被 core.create_task 用来从命令行参数上实例化这些类别(如有需要)。
-
worlds.py 文件,是可选的,可用于需要定义新环境或复杂环境的任务。
要添加你自己的任务:
-
(可选)实现 build.py 以下载任何所需的数据
-
实现 agents.py,至少包含一个 DefaultTeacher(扩展 Teacher 或它的一个衍生)
-
如果你的数据是 FB Dialog 格式的,那么属于 FbDialogTeacher 类别
-
如果不是 FB Dialog 格式:
-
如果你的数据是基于文本的,你可以使用扩展的 DialogTeacher,并因此要使用 core.data.TextData,在这种情况下,你仅需要编写你自己的 setup_data 函数,其可根据在 core.data 中所描述的格式而在数据之上提供一个 iterable.
-
如果你的数据使用了其它字段,那么就要编写你自己的 act() 方法,其提供了当你的任务每次被调用时的观察。
MTurk
ParlAI 的一个重要方面是与 Mechanical Turk 的无缝集成,可用于数据收集、训练和评估。在 ParlAI 中,人类 Turker 也被视为代理(agent),因此在一个标准的框架中可以进行人-人、人-bot、多人和多 bot 群聊等形式的对话,也可以按照需求切换角色,而无需对代理的代码进行修改。这是因为 Turker 也可以使用观察/动作(observation/action)词典中的字段来通过同样接口的一个版本进行接收和发送。我们在这第一版中提供了两个示例——收集数据和人类对 bot 的评估。
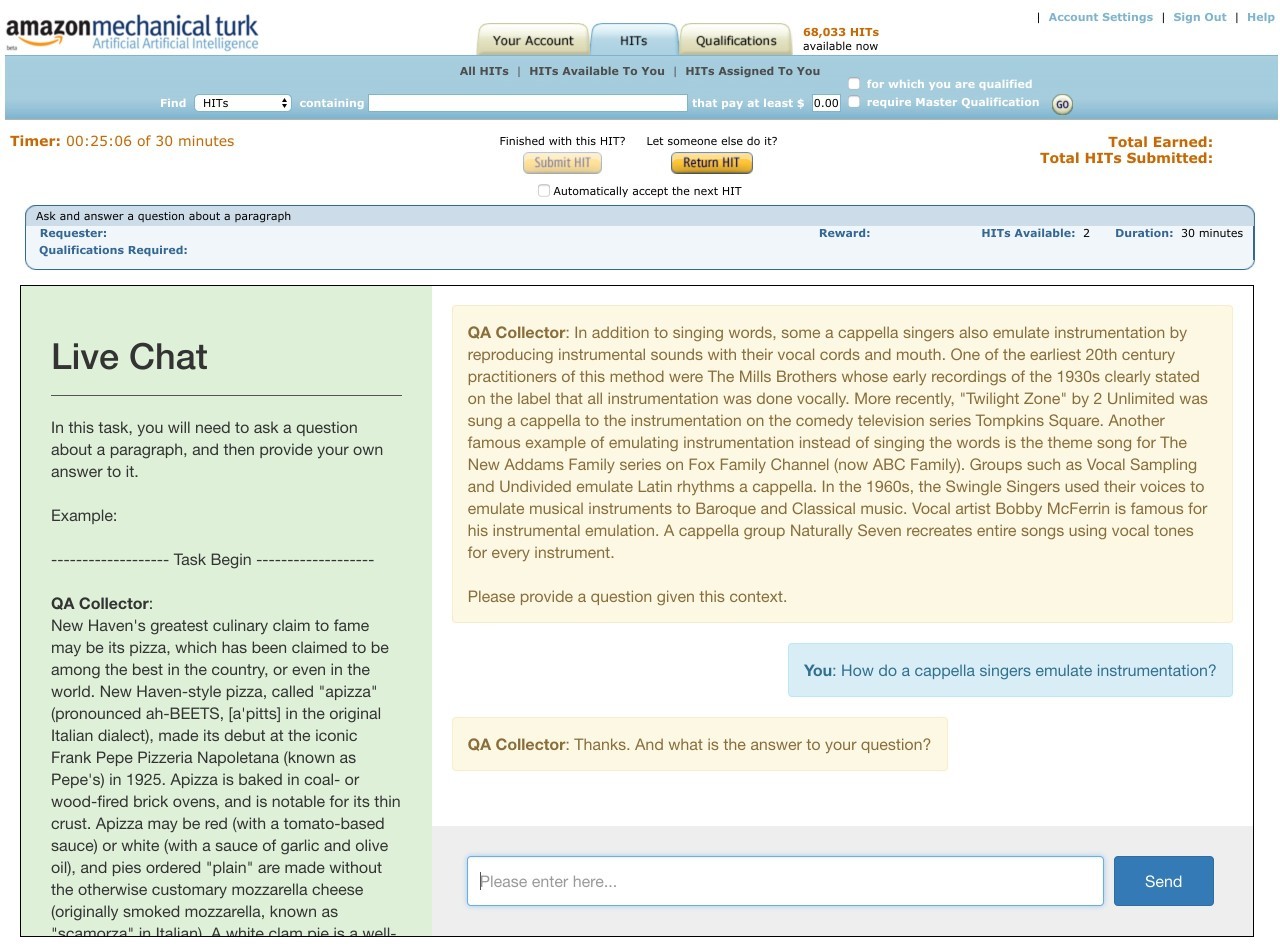
mturk 库包含以下目录和文件:
-
core:该目录包含了设置支持 MTurk 聊天接口的 AWS 后端的核心代码,以及用于 HIT 创建和许可的代码。
-
tasks:该目录包含了两个第一版提供的示例 MTurk 任务。
-
qa_data_collection:从 Turker 获取问题和答案,给出了 SQuAD 的一个随机段落
-
model_evaluator:在 Reddit 电影对话日志数据集上评估该信息检索基线模型
-
run_mturk.py:用于调用 mturk 核心代码的文件,包含用户指定的任务模块、对话日志模型代理、HIT 的数量和每个 HIT 的回报。
运行示例 MTurk 任务和代理:
-
在 run_mturk.py 中,去掉任务模块和你想使用的代理类别的注释
-
对于 create_hits 方法,如有需要,改变 num_hits 和 hit_reward。如果你想仅在 MTurk 沙箱中运行该样本,那么就将 is_sandbox 设置为 True;如果设置为 False,则就可让 Turker 来处理这个工作并得到报酬。
-
运行 python run_mturk.py
添加你自己的 MTurk 任务和对话模型:
-
在 mturk/tasks 目录为你自己的任务创建一个新的文件夹
-
部署 task_config.py,至少在 task_config 目录中包含以下字段:
-
hit_title:关于该 HIT 包含的任务类型的一个短的描述性标题。在 Amazon Mechanical Turk 网站上,该 HIT 标题以搜索结果的形式呈现,并且出现在该 HIT 被提及的任何地方。
-
hit_description:一个 description(描述)包含了该 HIT 所包含的任务类型的详细信息。在 Amazon Mechanical Turk 网站上,该 HIT 描述出现在搜索结果的扩展视图中,并且也会出现在该 HIT 和分配(assignment)屏幕上。
-
hit_keywords:描述该 HIT 的一个或多个词或短语,用逗号隔开。在 Amazon Mechanical Turk 网站上,这些词被用于搜索 HIT。
-
worker_agent_id:一个指示 Turker 在对话中的作用的短名字
-
task_description:一个详细的任务描述,将会出现在 HIT 任务预览页面,并会显示在聊天页面的左侧。支持 HTML 格式。
-
实现 agents.py,至少有一个从 Agent 扩展的代理类别。
-
编写你自己的 __init__() 方法以打包你的对话模型代理(具体示例可见 mturk/tasks/model_evaluator/agents.py 文件)。
-
编写你自己的 act() 方法,其会返回你的对话模型的响应,以及有助于 Turker 了解接下来应该做的事情的帮助文本。
-
在 run_mturk.py 文件中导入你的任务模块和代理类别,然后运行 python run_mturk.py
团队
ParlAI 目前由 Alexander H. Miller、Will Feng 和 Jason Weston 维护。其他主要贡献者还包括(不完整列表):Adam Fisch、Jiasen Lu、Antoine Bordes、Devi Parikh 和 Dhruv Batra。
证书
ParlAI 采用 BSD 授权。我们也提供了额外的专利授权。
点击阅读原文,报名参与机器之心 GMIS 2017 ↓↓↓


这篇文章还没有评论