NBA数据分析
赛题介绍:
这是科赛网的一个非商业练手项目,数据集内含从上世纪90年代开始到16-17赛季,包括NBA所有球员、球队的常规赛,季后赛数据,还收录有教练的执教数据,甚至包括球员各赛季的薪金数据。解决的问题就是对这个数据进行多维度分析,提炼有价值的结论。
我的开源:http://git.yoqi.me/lyq/NBA.git
作品浏览:https://www.kesci.com/apps/home/#!/lab/59b6ad982110010662302a60/v/latest/code
经历了一个堪称疯狂的休赛期,新赛季的NBA以一种超乎想象的方式拉开大幕。你可能想到了太多球员变动会带来磨合问题,想到了再夺冠军之后的勇士会在开局松懈,也想到了某些球队或许没有预期中那么不堪一击,但下面这些恐怕是你很难预料的。
当你看到詹姆斯和他的球队溃败于纽约尼克斯,看到锡伯杜带着一支防守全联盟倒数的球队时,一定会感叹一句:“什么情况!”
AAAlert使用K-Lab在线数据分析工具,构建梅西评分法模型对过往季后赛分数及逆行排名分析,带领大家探寻球队胜利的核心因素。
# coding:utf-8# import base tools import pandas as pd import numpy as np import matplotlib.pyplot as plt from matplotlib import style import warnings warnings.filterwarnings('ignore') style.use('ggplot') % matplotlib inline
“NBA变了”, 三年老球迷抽了一支烟,缓缓地说。
NBA真的变了吗?变在哪里?首先,我们考虑在不同赛季所有球队的表现究竟有何区别?
# 读取季后赛和常规赛数据 team_playoff = pd.read_csv('../input/NBAdata/team_playoff.csv') team_season = pd.read_csv('../input/NBAdata/team_season.csv')
# split season apart 自定义函数,整合出赛季标签便于后面分组;构造分差数据新特征 def add_season(date): season = np.zeros(len(date)) for i,d in enumerate(date.str.split('-').str[0:2]): season[i] = int(d[0]) if int(d[1])<7 else int(d[0])+1 return season# generate score_diff_team_a = score(team_a) - score(team_b) def add_score_diff(res): diff = np.zeros(len(res)) for i,d in enumerate(res.str.split('-')): diff[i] = abs(int(d[1][0:-3]) - int(d[0][3:])) return diff team_season['分差'] = add_score_diff(team_season['比分']) team_playoff['分差'] = add_score_diff(team_playoff['比分']) team_season['赛季'] = add_season(team_season.时间) team_playoff['赛季'] = add_season(team_playoff.时间) # replace ['L'/'W'] with [-1/1] team_season['结果'].replace(['L','W'],[-1,1], inplace=True) team_playoff['结果'].replace(['L','W'],[-1,1], inplace=True)
下面从常规赛和季后赛对联盟的赛季发展进行分析。
常规赛
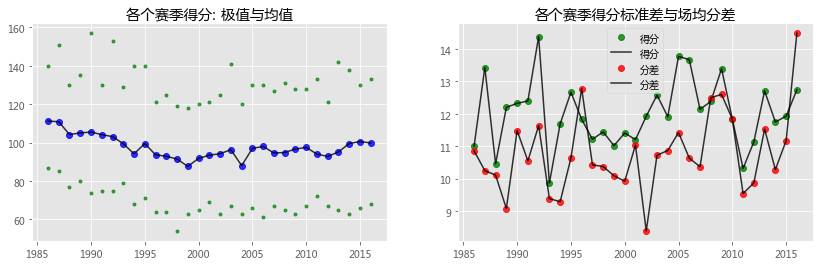
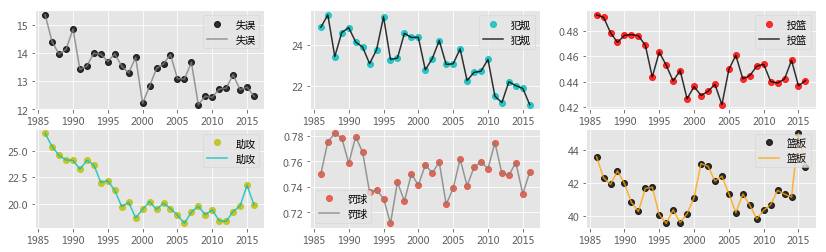
# 常规赛分析 temp = team_season[['得分','赛季','分差','篮板','犯规','罚球','罚球命中','罚球出手','失误','助攻','投篮']].groupby('赛季') plt.figure(figsize=(14,4)) plt.subplot(121) plt.title('各个赛季得分: 极值与均值') plt.plot(temp['得分'].min(),'g.',alpha=0.7) plt.plot(temp['得分'].max(),'g.',alpha=0.7) plt.plot(temp['得分'].mean(),'bo',temp.mean()['得分'],'k',alpha=0.8) plt.subplot(122) plt.title('各个赛季得分标准差与场均分差') plt.plot(temp['得分'].std(),'go',temp['得分'].std(),'k',alpha=0.8) plt.plot(temp['分差'].mean(),'ro',temp['分差'].mean(),'k',alpha=0.8) plt.legend() plt.figure(figsize=(14,4)) plt.subplot(131) plt.plot(temp.min()['篮板'],'g.',alpha=0.7) plt.plot(temp.max()['篮板'],'g.',alpha=0.7) plt.plot(temp.mean()['篮板'],'o',temp.mean()['篮板'],'k',alpha=0.8) plt.subplot(231) plt.plot(temp['失误'].mean(),'ko',temp['失误'].mean(),'grey',alpha=0.8);plt.legend() plt.subplot(234) plt.plot(temp['助攻'].mean(),'yo',temp['助攻'].mean(),'c',alpha=0.8);plt.legend() plt.subplot(232) plt.plot(temp['犯规'].mean(),'co',temp['犯规'].mean(),'k',alpha=0.8);plt.legend() plt.subplot(235) plt.plot(temp['罚球'].mean(), 'o',temp['罚球'].mean(),'grey',alpha=0.8);plt.legend() plt.subplot(233) plt.plot(temp['投篮'].mean(),'ro',temp['投篮'].mean(),'k',alpha=0.8);plt.legend() plt.subplot(236) plt.plot(temp['篮板'].mean(),'ko',temp['篮板'].mean(),'orange',alpha=0.8);plt.legend() Out[4]: <matplotlib.legend.Legend at 0x7f3cba0ac898> 季后赛 In [5]: # 季后赛分析 temp = team_playoff[['得分','赛季','分差','篮板','犯规','罚球','罚球命中','罚球出手','失误','助攻','投篮']].groupby('赛季') plt.figure(figsize=(14,4)) plt.subplot(121) plt.title('各个赛季得分: 极值与均值') plt.plot(temp['得分'].min(),'g.',alpha=0.7) plt.plot(temp['得分'].max(),'g.',alpha=0.7) plt.plot(temp['得分'].mean(),'bo',temp.mean()['得分'],'k',alpha=0.8) plt.subplot(122) plt.title('各个赛季得分标准差与场均分差') plt.plot(temp['得分'].std(),'go',temp['得分'].std(),'k',alpha=0.8) plt.plot(temp['分差'].mean(),'ro',temp['分差'].mean(),'k',alpha=0.8) plt.legend() plt.figure(figsize=(14,4)) plt.subplot(131) plt.plot(temp.min()['篮板'],'g.',alpha=0.7) plt.plot(temp.max()['篮板'],'g.',alpha=0.7) plt.plot(temp.mean()['篮板'],'o',temp.mean()['篮板'],'k',alpha=0.8) plt.subplot(231) plt.plot(temp['失误'].mean(),'ko',temp['失误'].mean(),'grey',alpha=0.8);plt.legend() plt.subplot(234) plt.plot(temp['助攻'].mean(),'yo',temp['助攻'].mean(),'c',alpha=0.8);plt.legend() plt.subplot(232) plt.plot(temp['犯规'].mean(),'co',temp['犯规'].mean(),'k',alpha=0.8);plt.legend() plt.subplot(235) plt.plot(temp['罚球'].mean(), 'o',temp['罚球'].mean(),'grey',alpha=0.8);plt.legend() plt.subplot(233) plt.plot(temp['投篮'].mean(),'ro',temp['投篮'].mean(),'k',alpha=0.8);plt.legend() plt.subplot(236) plt.plot(temp['篮板'].mean(),'ko',temp['篮板'].mean(),'orange',alpha=0.8);plt.legend()
季后赛
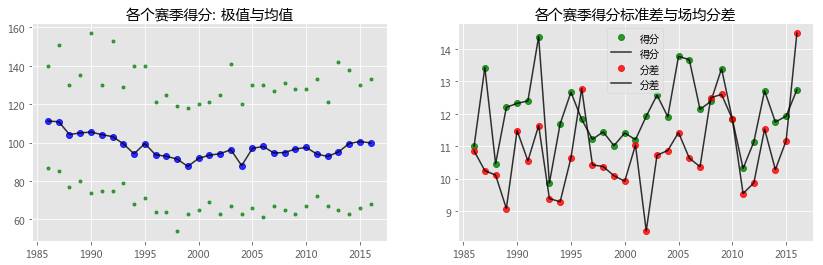
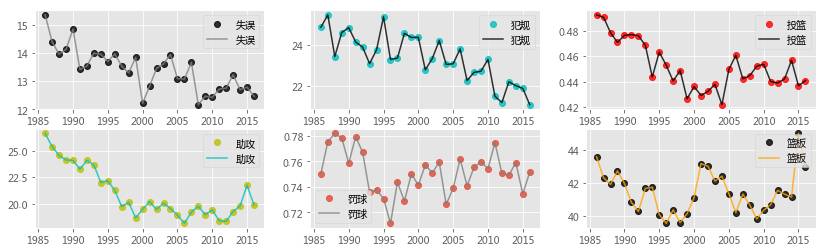
# 季后赛分析 temp = team_playoff[['得分','赛季','分差','篮板','犯规','罚球','罚球命中','罚球出手','失误','助攻','投篮']].groupby('赛季') plt.figure(figsize=(14,4)) plt.subplot(121) plt.title('各个赛季得分: 极值与均值') plt.plot(temp['得分'].min(),'g.',alpha=0.7) plt.plot(temp['得分'].max(),'g.',alpha=0.7) plt.plot(temp['得分'].mean(),'bo',temp.mean()['得分'],'k',alpha=0.8) plt.subplot(122) plt.title('各个赛季得分标准差与场均分差') plt.plot(temp['得分'].std(),'go',temp['得分'].std(),'k',alpha=0.8) plt.plot(temp['分差'].mean(),'ro',temp['分差'].mean(),'k',alpha=0.8) plt.legend() plt.figure(figsize=(14,4)) plt.subplot(131) plt.plot(temp.min()['篮板'],'g.',alpha=0.7) plt.plot(temp.max()['篮板'],'g.',alpha=0.7) plt.plot(temp.mean()['篮板'],'o',temp.mean()['篮板'],'k',alpha=0.8) plt.subplot(231) plt.plot(temp['失误'].mean(),'ko',temp['失误'].mean(),'grey',alpha=0.8);plt.legend() plt.subplot(234) plt.plot(temp['助攻'].mean(),'yo',temp['助攻'].mean(),'c',alpha=0.8);plt.legend() plt.subplot(232) plt.plot(temp['犯规'].mean(),'co',temp['犯规'].mean(),'k',alpha=0.8);plt.legend() plt.subplot(235) plt.plot(temp['罚球'].mean(), 'o',temp['罚球'].mean(),'grey',alpha=0.8);plt.legend() plt.subplot(233) plt.plot(temp['投篮'].mean(),'ro',temp['投篮'].mean(),'k',alpha=0.8);plt.legend() plt.subplot(236) plt.plot(temp['篮板'].mean(),'ko',temp['篮板'].mean(),'orange',alpha=0.8);plt.legend()
NBA展现的30年历程,不只是成长,还有周期!
-
1985年起,场均普遍达到110分,联盟实力相对均衡。接下来的5年中NBA开始动荡,实力差距变大。
-
巨头出现:伯德和凯尔特人达到了极盛时期、乔丹一战封神、斯特恩新官上任三把火,开始改革选秀制度、休斯敦双塔首次震撼世人……
-
至1990年左右,得分标准差历史最高,联盟内差距达到顶峰;
-
90年后,得分、分差、不断下滑,在此期间,NBA的规则也在不断完善:裁判数、暂停数、恶犯、三分都在逼近当代的篮球规则体系
当然,规则都是用来权衡的。步入21世纪,NBA场均得分历史最低,联盟推出了no-handcheck规则,鼓励进攻,得分回升,实力差异扩大。
从上图的多项数据中仿佛可以看出NBA变迁的两种形式:
-
震荡周期性,主要表现在得分、篮板、分差、助攻、罚球与投篮命中率上,这类数据往往反映了联盟的竞赛风格与内部实力差距。
-
单向趋势性,主要表现在失误、犯规、投篮命中率上,这类数据体现了NBA战术、规则的完善与球员训练素质的逐渐进步 </li> ### 注意,以上特征在季后赛这种关乎生死与最终荣誉的比赛上尤其明显,也就是说:目前还不是全部在瞎编(#滑稽#)。
最有趣的年代是1994-1999年这一段时间,在篮板、投篮命中率、罚球以及场均分差上均是低谷时期。但是往往有不少球迷反而迷恋那个时代,慢进攻节奏,中投为主,缺少三分与罚球等等现代进攻技巧的所谓“效率低下”打法,或许这就是篮球的魅力!
说了这么多,NBA的各项数据,你方唱罢我登场,起起伏伏,仿佛天道轮回,2015年分差(实力差距)沉寂之后,何者独领风骚呢!
:)某杜姓民工的决定,我想,正式拉开了又一个轮回的序幕
看完了这么啰嗦的口水话,我们对NBA的发展有了初步印象。的确,联盟发展存在较大的差异性,那么如何在这些差异性中求得最终的赢家呢?
引入假设
-
NBA各个时期的夺冠球队就是最强球队——也许胜负有巧合,但夺冠没有
-
夺冠的球队都是相似的,不夺冠各有各的不幸
-
为消除不同时期的数据分布差异,赛季数据按赛季分组正则化
-
只有季后赛球队参与建模,避免常规赛的各种奇葩情况
-
各位看官没有钦定的情感倾向——这条最严格(扯淡)。
梅西法排序得分
梅西法是根据球队之间某项数据差异来构建线性方程组求解得到排名得分的经典方法。
相关链接:
http://blog.csdn.net/feitongxunke/article/details/52077812
梅西法可以认为是球队在此数据上的和对手对比出的攻防综合表现。
def Messi_rank(season_data, index): train = season_data[['球队',index]].groupby('球队').sum() A = -np.ones((train.shape[0],train.shape[0])) for i in range(0,train.shape[0]-1): A[i,i] += train.shape[0] A[i+1] = 1 train.iloc[-1] = 0 rank = np.dot(np.linalg.inv(A),train.values) rank = pd.DataFrame(rank,index=train.index) return rank group_playoff = team_playoff.groupby('赛季') messi_res = []for s,d in group_playoff: messi_res.append(Messi_rank(d,'分差'))fig, axes = plt.subplots(nrows=2, ncols=3,figsize=(16,8)) r = c = 0for i,d in enumerate(messi_res): if(i+1986 in [1996,1997,1998,2001,2014,2016]): d.sort_values(by=0).plot(kind='bar',ax=axes[r,c],title=i+1986,label=None,legend=None) c += 1 if(c==3): c = 0;r=1
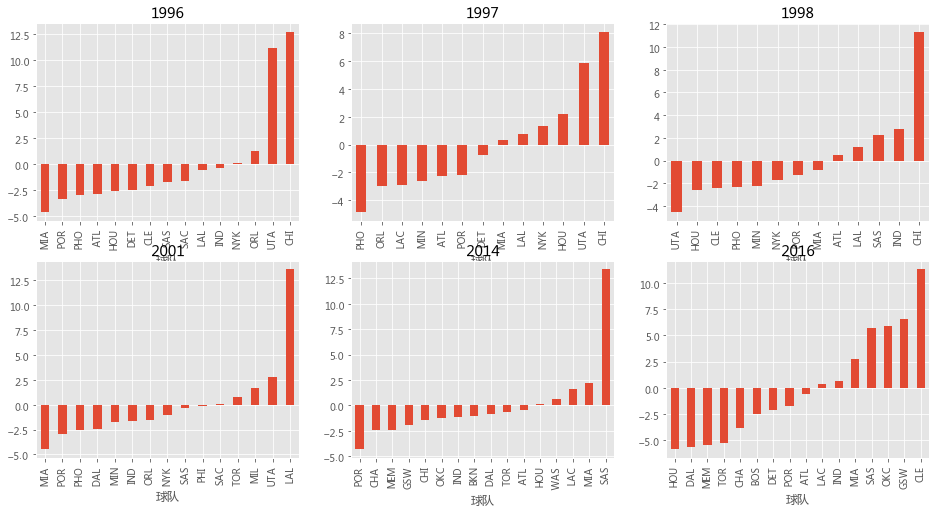
从梅西法,我选取了几个比较有竞争力的年份:
-
梅西法评分最高的年份出现在96公牛,01湖人,14马刺三个年代,均大于12.5
-
从评分的分布看出96公牛遇到劲敌96犹他,二者称霸季后赛;但是01湖人、14马刺均是毫无疑问的全面压制对手
-
梅西法评价结果基本符合当时比赛的情形
建模思路
-
寻找最强球队本质上类似一个排序问题,因此采用近似AUC的评估函数与优化方法
-
对每一个赛季而言,是否夺冠作为label
-
每个赛季数据内部正则化,并单独训练模型,产出30个模型
-
最终将所有年代夺冠球队数据放在一个组内,进行正则化并以30个模型的集成结果为定论
-
输出结果,如果有空,那么分析一下模型内部参数的意义。
data = team_playoff.groupby(['赛季','球队']) features = team_playoff.columns[5:-1] print('Simple Features: nt',features) gtrain_data = data.mean()[features].reset_index() winner_count = data.结果.sum() winner_count = winner_count.reset_index() winner_count.head()# 建立历年冠军index与冠军数据集 champs = None champs_index = winner_count.groupby('赛季').apply(lambda t: t[t['结果']==t['结果'].max()]) champs_index = champs_index.drop([(2013.0,411)]) # 数据有些问题,根据净胜结果选取冠军同时出现了2013马刺和热火,因此删除 champs = team_playoff.merge(champs_index, on=['赛季','球队'],how='inner').groupby(['赛季','球队']).mean()[features]# 最终获得的概率输出如图所示 cols = champs_index['赛季'].astype(str).str[0:4] + '-' + champs_index['球队'] finals = pd.DataFrame(finals) finals.columns = cols.values ranks = []for name,row in finals.iterrows(): row = np.array(row) row[np.argsort(row)] = range(0,len(row)) ranks.append(row) ranks = pd.DataFrame(ranks, columns=finals.columns) ranks.sum().sort_values().plot(kind='barh',figsize=(10,6),color='darkred')finals = [] features_importance = [] # 记录最终结果和特征重要性(模型内参数)for season,tr in gtrain_data.groupby('赛季'): tr = tr[features] score = winner_count[winner_count['赛季']==season]['结果'] score = (score==max(score))*1 model1 = LR() model1.fit(tr,score) features_importance.append(model1.coef_[0]) finals.append(model1.predict_proba(champs)[:,1]) print(season,',',model1.score(tr,score),end='| ') if(season%5==0): print('n')# 最终获得的概率输出如图所示 cols = champs_index['赛季'].astype(str).str[0:4] + '-' + champs_index['球队'] finals = pd.DataFrame(finals) finals.columns = cols.values ranks = []for name,row in finals.iterrows(): row = np.array(row) row[np.argsort(row)] = range(0,len(row)) ranks.append(row) ranks = pd.DataFrame(ranks, columns=finals.columns) ranks.sum().sort_values().plot(kind='barh',figsize=(10,6),color='darkred')
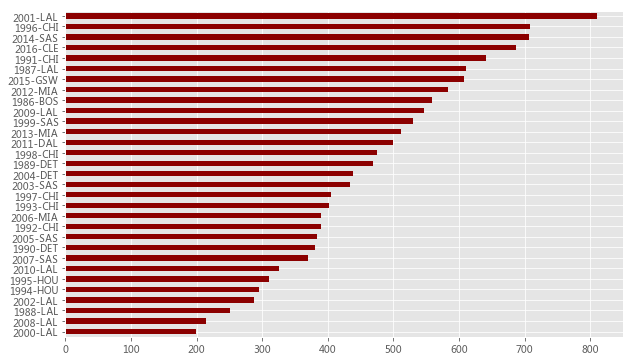
# 这里使用seaborn来绘制一个colormap 每个模型的对球队的概率输出 plt.figure(figsize=(15,10)) _,ax = plt.subplots() ax.set_xticks(np.arange(ranks.shape[1])+0.5, minor=False) ax.set_yticks(np.arange(ranks.shape[0])+0.5, minor=False) ax.pcolor(ranks.T,cmap=plt.cm.Purples, alpha=0.8) ax.set_xticklabels(ranks.T.columns, minor=False) ax.set_yticklabels(ranks.T.index, minor=False)
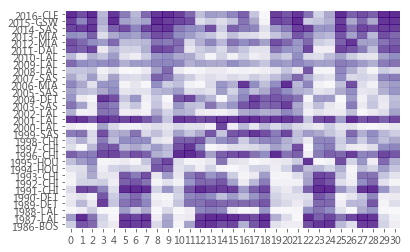
上面的模型参数看起来很复杂,但是我们尝试去解释的话却也能看出一些门道,如下图:
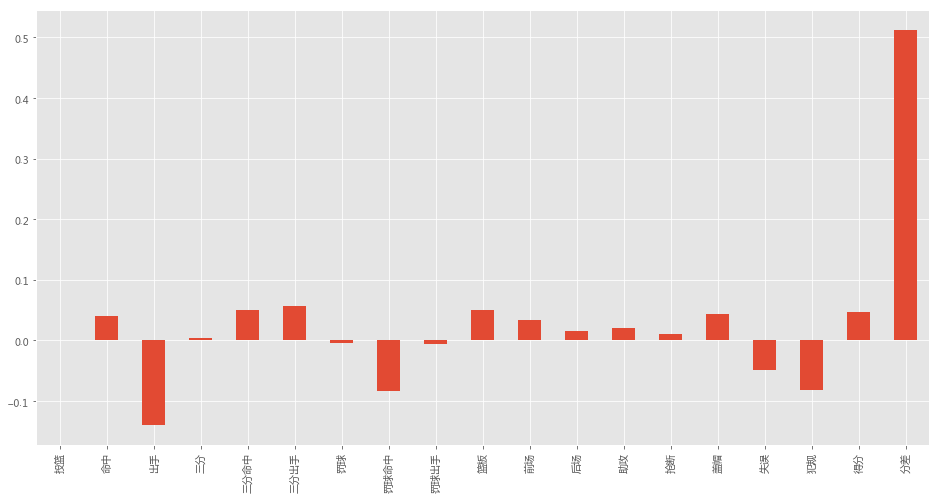
-
看上去我们的模型中引入的分差过分重要了(当你比对手的分差是正数的时候,你很难输球)
-
有趣的是,罚球三项数据均和最终结果呈负相关……登哥,你可长点心吧。
-
投篮看上去和胜负无所谓;三分甩的多竟然比三分命中率高还重要;但是不要出手太多,容易输哦;失误和犯规少一点,比赛更容易赢……
-
当你的几项积极的数据都包围对手的时候,赢球还不是小目标吗?

这篇文章还没有评论