最全技术图谱!一文掌握人工智能各大分支技术
作者 | Stefan Kojouharov
编译 | 聂震坤
在过去的几个月中,我一直在收集有关人工智能的相关资料。随着各种的问题被越来越频繁的提及,我决定整理并分享有关人工智能、神经网络、机器学习、深度学习与大数据的技术合辑。同时为了内容更加生动易懂,本文将会针对各个大类展开详细解析。
神经网络
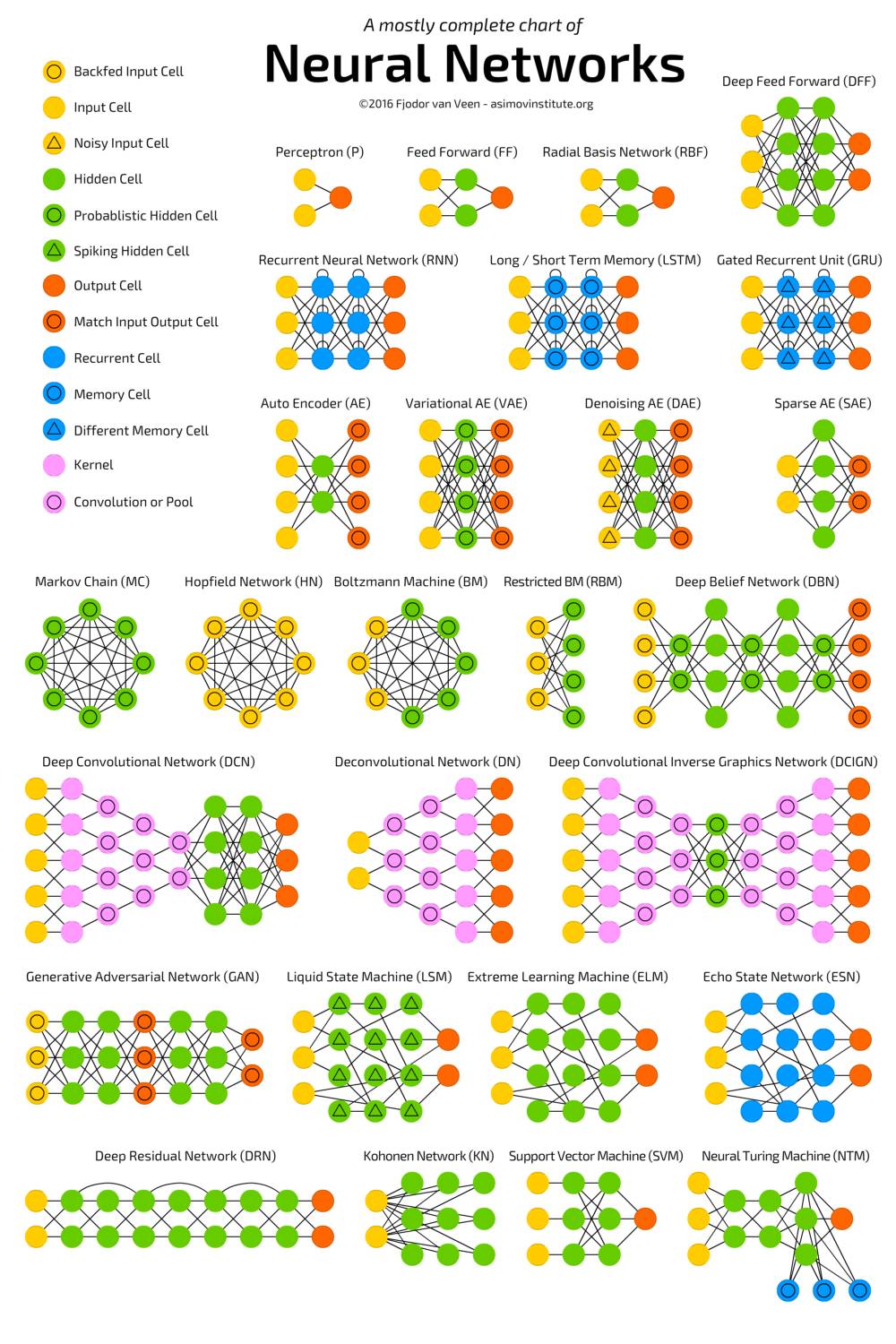


机器学习

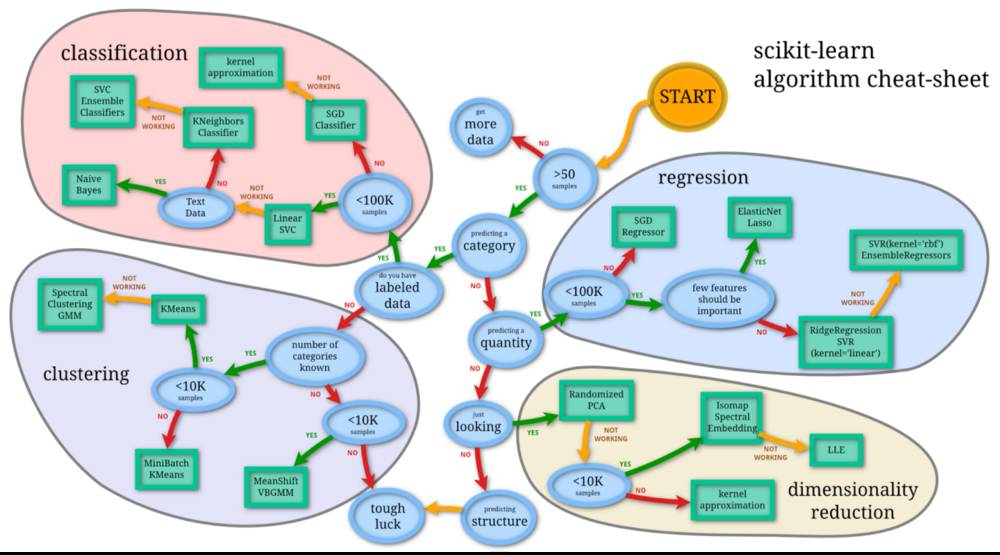
机器学习: Scikit-learn 算法
此部分内容可以帮助你解决机器学习中最难的部分,即找到正确的估计器(Estimator)。下图可帮助快速查找文档与简介,更快了解问题并找到解决方法。
Scikit-Learn
Scikit-learn(更正式的叫法为 scikits.learn)是 Python 的一个用于机器学习的免费库。库中有大量的分类,回归与聚类算法,并支持向量机、随机森林、梯度提升、 K 均值与 DBSCAN。 旨在与 Python 数字库 NumPy 和科学库 SciPy 进行交互。

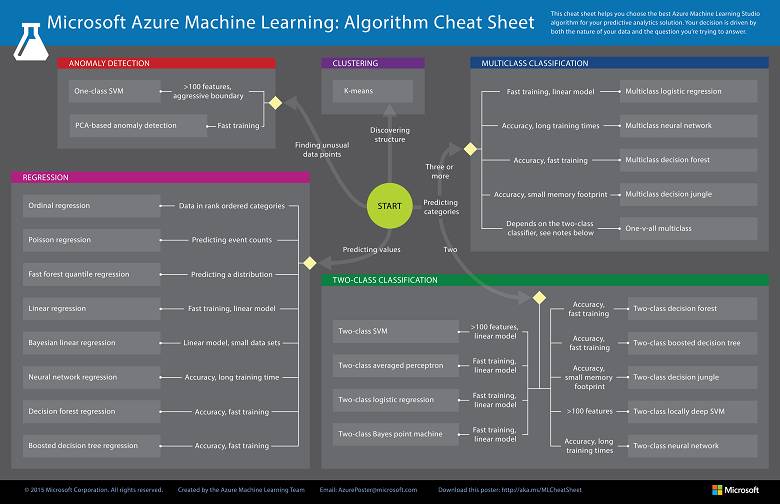
机器学习:算法
此部分旨在介绍如何根据预测分析方案选择合适的机器学习算法。下图可以根据数据性质提出最佳算法。
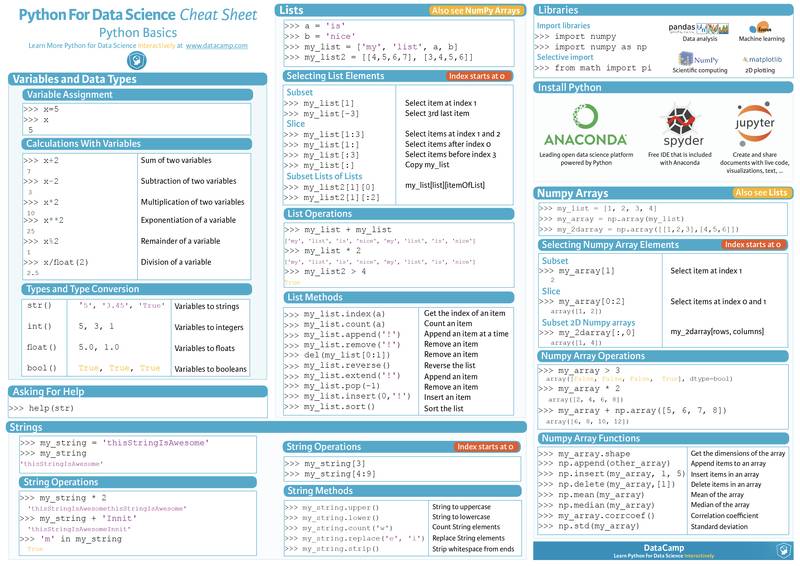
用于数据科学的 Python

TensorFlow
谷歌于 2017 年 5 月宣布了第二代 TPU 并在谷歌计算引擎中加入了对 TPU 的支持。第二代 TPU 拥有高达 180 万亿次浮点运算性能(180 teraflops)。当 64 个 TPU 组合在一起时,可以提供高达 11.5 千万亿次浮点运算性能(11.5 petaflops)。

Keras
2017 年,谷歌在 TensorFlow 的核心库中加入了对 Keras 的支持。有学者认为,认为相较于端到端的机器学习框架,Keras 更适合作为接口来使用。它提供了更高级别,更直观的抽象集合,使得无论后端科学计算库如何,都可以轻松配置神经网络。

Numpy
NumPy 是针对 Python 的 CPython 参考实现,是一个非优化的字节码解释器。针对目前版本的Python编写数学算法的运行速度相对较慢的问题,Numpy 使用多维数组和函数与运算符来改写部分代码来提高运行效率。

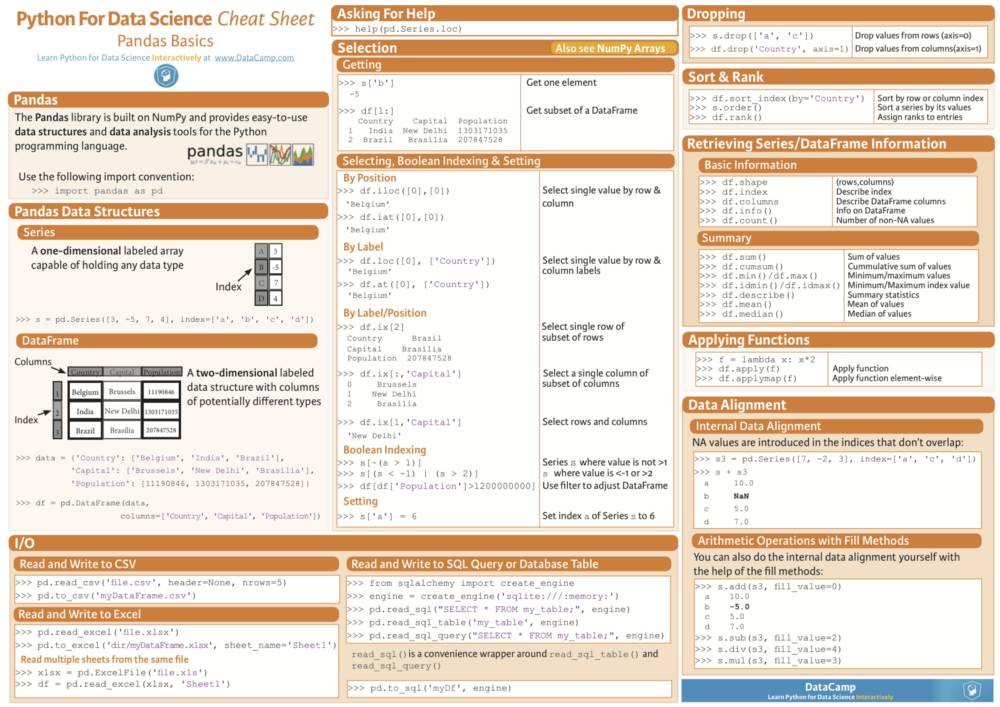
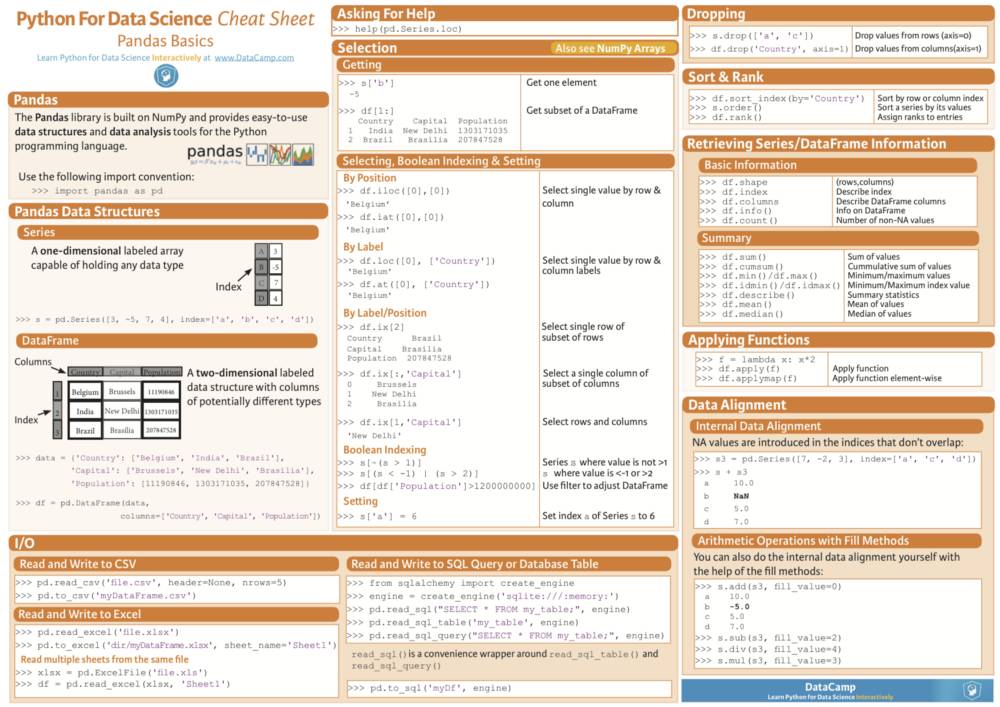
Pandas
名称 “Pandas” 源于“面板数据”(Panel Data)一词,是多维结构化数据集的计量经济学术语。
数据预处理
数据预处理一词已经开始渗透进流行文化中。在2017年电影“金刚:骷髅岛”中,演员马克·埃文·杰克逊(Marc Evan Jackson)饰演的角色为“我们的数据处理者–史蒂夫·伍德沃德。


用 Dplyr 与 Tidyr 进行数据预处理

SciPy
SciPy 是基于 NumPy 数组对象进行构建,为 NumPy 堆栈的一部分。包括 Matplotlib,pandas 和 SymPy 等工具,以及扩展的科学计算库集。该 NumPy 堆栈与其他应用程序(如MATLAB,GNU Octave 和 Scilab)具有类似的使用者。 NumPy 堆栈有时也被称为 SciPy 堆栈。

Matplotlib
Matplotlib 是 Python 编程语言及其数学数学扩展 NumPy 的绘图库。它提供了面向对象的API,用于使用 Tkinter,wxPython,Qt 或 GTK +等通用 GUI 工具包将图形嵌入到应用程序中。还有一个基于状态机(如 OpenGL)的程序 “pylab” 接口。接口类似 MATLAB,但不鼓励使用。
Pyplot 是一个 matplotlib 模块,他提供了一个类似 MATLAB 的界面。Pyplot 拥有跟MATLAB 一样易上手,兼容 Pyhton 并且免费的优点。

数据可视化


PySpark

原文:Cheat Sheets for AI, Neural Networks, Machine Learning, Deep Learning & Big Data
审校:屠敏
7月22-23日,本年度中国人工智能技术会议最强音——2017 中国人工智能大会(CCAI 2017)即将在杭州国际会议中心拉开序幕。汇集超过40位学术带头人、8场权威专家主题报告、4场开放式专题研讨会、超过2000位人工智能专业人士将参与本次会议.
目前,大会 8 折优惠门票正在火热发售中,扫描下方二维码或点击【阅读原文】火速抢票。


这篇文章还没有评论