饿了么推荐系统:从0到1
本文由携程技术中心投递,ID:ctriptech。作者:饿了么数据运营部资深算法工程师陈一村,在携程个性化推荐与人工智能Meetup上的分享。
陈一村2016年加入饿了么,现从事大数据挖掘和算法相关工作,包括推荐系统、用户画像等。
随着移动互联网的发展,用户使用习惯日趋碎片化,如何让用户在有限的访问时间里找到想要的产品,成为了搜索/推荐系统演进的重要职责。作为外卖领域的独角兽, 饿了么拥有百万级的日活跃用户,如何利用数据挖掘/机器学习的方法挖掘潜在用户、增加用户粘性,已成为迫切需要解决的问题。
个性化推荐系统通过研究用户的兴趣偏好,进行个性化计算,发现用户的兴趣点,从而引导用户发现自己的信息需求。一个好的推荐系统不仅能为用户提供个性化的服务,还能和用户之间建立密切关系,让用户对推荐产生依赖。
本次分享介绍饿 了么如何从0到1构建一个可快速迭代的推荐系统,从产品形态出发,包括推荐模型与特征工程、日志处理与效果评估,以及更深层次的场景选择和意图识别。
在携程个性化推荐与人工智能meetup上,已经就以上几部分做了整体上的说明,本文将就其中模型排序与特征计算的线上实现做具体说明,同时补充有关业务规则相关的洗牌逻辑说明,力图从细节上还原和展示饿了么美食推荐系统。
一、模型排序
1、设计流程
对于任何一个外部请求, 系统都会构建一个QueryInfo(查询请求), 同时从各种数据源提取UserInfo(用户信息)、ShopInfo(商户信息)、FoodInfo(食物信息)以及ABTest配置信息等, 然后调用Ranker排序。以下是排序的基本流程(如下图所示):
-
调取RankerManager, 初始化排序器Ranker:
-
根据ABTest配置信息, 构建排序器Ranker;
-
调取ScorerManger, 指定所需打分器Scorer(可以多个); 同时, Scorer会从ModelManager获取对应Model, 并校验;
-
调取FeatureManager, 指定及校验Scorer所需特征Features。
-
-
调取InstanceBuilder, 汇总所有打分器Scorer的特征, 计算对应排序项EntityInfo(餐厅/食物)排序所需特征Features;
-
对EntityInfo进行打分, 并按需对Records进行排序。
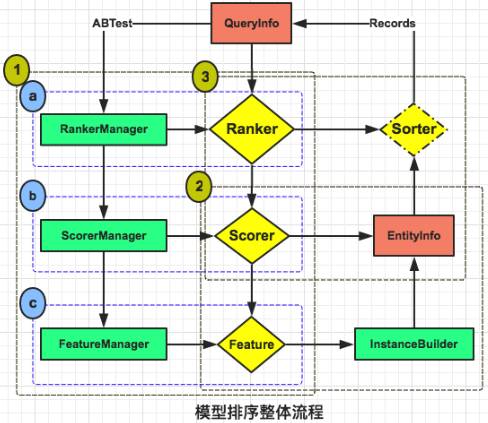
这里需要说明的是:任何一个模型Model都必须以打分器Scorer形式展示或者被调用。主要是基于以下几点考虑:
-
模型迭代:比如同一个Model,根据时间、地点、数据抽样等衍生出多个版本Version;
-
模型参数:比如组合模式(见下一小节)时的权重与轮次设定,模型是否支持并行化等;
-
特征参数:特征Feature计算参数,比如距离在不同城市具有不同的分段参数。
2、排序逻辑
对于机器学习或者学习排序而言, 多种模型的组合(Bagging, Voting或Boosting等)往往能够带来稳定、有效的预测结果。所以, 针对当前美食推荐项目, 框架结合ABTest系统, 支持single、linear及multi三种组合模式, 具体说明如下:
-
single:单一模式, 仅用一个Scorer进行排序打分;
-
linear:线性加权模式, 指定一系列Scorer以及对应的权重, 加权求和;
-
multi:多轮排序模式, 每轮指定Scorer, 仅对前一轮的top N进行排序。
具体说明如下:
单一模式:rankType=single
对于单一模式, 仅有一个Scorer, 且不存在混合情况, 所以只要简单对Scorer的打分进行排序即可, 故在此不做详细展开。ABTest配置格式如下表:

线性加权模式:rankType=linear
对于线性加权模式, 在单一模式配置的基础上,需要在ABTest配置每个Scorer的权重, 格式如下表所示:

当LinearRanker初始化时, 会校验和初始化所有打分器Scorer。之后, 按照以下步骤对餐厅/食物列表进行排序, 详见下图(左):
-
特征计算器InstanceBuilder调用ScorerList, 获取所有所需特征Feature并去重;
-
InstanceBuilder对所有餐厅/食物进行特征计算, 详见特征计算;
-
ScorerList中所有Scorer对所有餐厅/食物依次进行打分;
-
对所有Scorer打分进行加权求和, 之后排序。
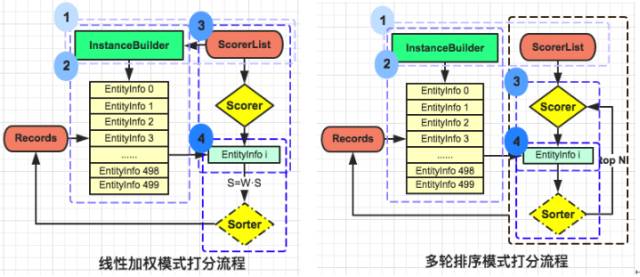
多轮排序模式:rankType=multi
对于多轮排序模式, 每轮设定一个Scorer, 对前一轮top=Num个餐厅/食物进行排序, 故在ABTest中需要设定每个Scorer的轮次(round)和排序数(num), 格式如下表。

MultiRanker初始化与特征计算与LinearRanker类似, 具体步骤详见上图(右):
-
特征计算器InstanceBuilder调用ScorerList, 获取所有所需特征Feature并去重;
-
InstanceBuilder对所有餐厅/食物进行特征计算, 详见特征计算;
-
Scorer按轮次(round)对top=Num餐厅/食物进行打分;
-
对top=Num餐厅/食物按当前Scorer的打分进行排序。
重复步骤3、4, 直到走完所有轮次。
在初始化阶段, Ranker根据ABTest配置信息指定算法版本(algoVersion)、排序类型(rankType)、排序层级(rankLevel)及相关打分器(ScorerList)。
3、模型定义
对于线上任何Model,ModelManager 都会通过以下流程获取相应实例和功能(如下图所示):
-
模型实例化时的构造函数BaseModel()和校验函数validate();
-
通过FeatureManager获取对应Model的特征Feature:abstract getFieldNames()/getFeatures();
-
传入Model的特征, 获取预测分数:abstract predict(Map
对于Model的迭代和更新、以及之后的Online Learning等, 通过ModelManager对接相应服务来实现。
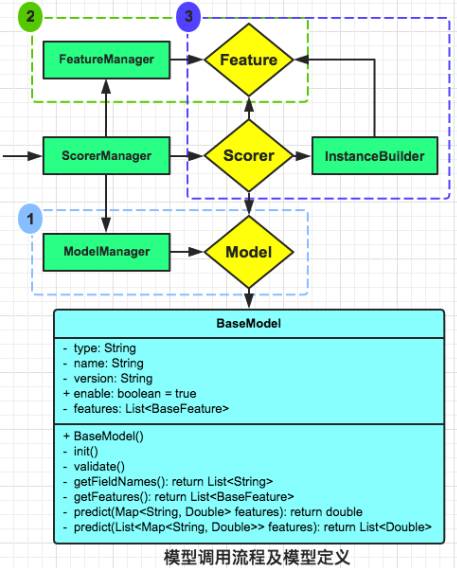
如上图所示, 对于任何一个可被Scorer直接调用Model, 都需要实现以下接口:
-
可供ModelManager进行Model实例化的BaseModel() 和初始化的init()
;
-
可供Scorer/InstanceBuilder获取特征项的 getFieldNames()/getFeatures();
-
可供Scorer调用进行打分的 predict(Map<K, V> values) 和 predict(List<Map<K, V> values)
。
二、特征计算
1、设计流程
不同于离线模型训练,线上特征计算要求低延迟、高复用、强扩展,具体如下:
-
低延迟:针对不同请求Query,能够快速计算当前特征值,包括从各种DB、Redis、ES等数据源实时地提取相关数据进行计算;
-
高复用:对于同类或者相同操作的特征,应该具有高复用性,避免重复开发,比如特征交叉操作、从USER/SHOP提取基本字段等;
-
强扩展:能够快速、简单地实现特征,低耦合,减少开发成本。
根据以上系统设计要求, 下图给出了特征计算的设计流程和特征基类说明。

具体说明如下:
-
FeatureManager:特征管理器, 用于特征管理, 主要功能如下:
a.特征管理:包括自定义特征、基础特征、实时特征、复合特征等;
b.特征导入:自定义特征静态代码注册,其他特征数据库导入;
c.特征构建:CompsiteFeature类型特征构建。
-
InstanceBuilder:特征构建器, 用于计算餐厅/食物特征, 具体步骤如下:
a.从每个Scorer获取Feature列表, 去重, 依赖计算, 最后初始化;
b.层级、并行计算每个EntityInfo的特征值(之后会考虑接入ETL, 用于Online Learning)。
2、特征定义
上图给出了特征基类说明, 以下是具体的字段和方法说明:
-
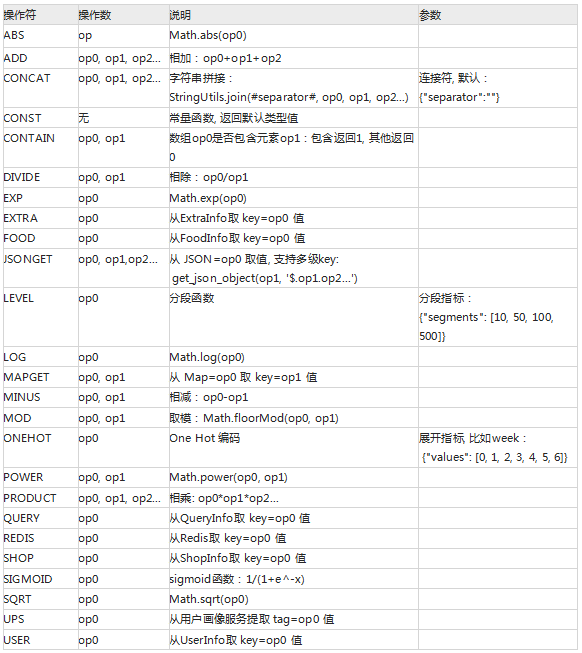
type: 特征类型, 现有query、shop、food, 表示Feature的特征维度 (粒度)
-
operate: CompositeFeature专属, 特征操作, 指定当前特征行为, 比如ADD、MAPGET等
-
name: 特征名称
-
weight: 权重, 简单线性模型参数
-
retType: 特征返回字段类型
-
defValue: 特征默认返回值
-
level: CompositeFeature专属, 当前特征层次, 用于特征层次计算
-
operands: CompositeFeature专属, 特征操作数, 前置特征直接依赖
-
dependencies: CompositeFeature专属, 特征依赖
-
*init(): 特征初始化函数
-
*initOther(QueryInfo): InstanceBuilder调用时实时初始化, 即传入当前特征参数
-
*evaluate(QueryInfo, EntityInfo, StringBuilder): 用于餐厅/食物维度的特征计算
根据上两小节设计流程和基类定义的说明, 我们能够非常快速、简便地实现一个自定义特征, 具体流程如下(score为例, 对应类名XXXFeature):
特征类实现:
-
建立XXXFeature, 并继承BaseFeature/CompositeFeature;
-
实现init(), 设置typename(defValueweight可选)等;
-
实现initOther(), 设置特征参数, 包括infoMap;
-
实现evaluate(), 具体包括特征计算的详细逻辑, 对于返回数值的特征。
特征注册:
-
在FeatureManager中注册, 或者在后台特征管理系统中注册;
-
考虑到代码中不允许出现明文常量, 故需在FeatureConsts中添加常量定义。
3、特征分类
(1) 基础特征:
基础特征为线上可以通过配置特征名直接从SHOP/USER获取特征值的特征, 比如:shop_meta_、user_meta_、food_meta_等, 详细说明如下表,其从本质上来讲等同于特征操作符(复合特征)。

(2) 实时特征:
实时特征来源于Kafka与Storm的日志实时计算,存于Redis,比如:用户食物搜索与点击信息,实例如下表。

(3) 自定义特征:
线上除CompositeFeature特征外, 所有XXXFeature均为自定义特征, 在此不再累述。
(4) 复合特征(CompositeFeature):
用户特征组合的复杂操作, 比如下表所示(部分)
三、洗牌逻辑
1、洗牌类型
很多时候, 基于算法模型的结果能够给出数据层面的最佳结果, 但是不能保证推荐结果符合人的认知, 比如基于CTR预估的逻辑, 在结果推荐上会倾向于用户已点过或已购买过的商户/食物, 这样就使得推荐缺少足够的兴趣面。所以, 为了保证推荐结果与用户的相关性, 我们会保留算法模型的结果; 同时, 为了保证结果符合认知, 我们会人为地添加规则来对结果进行洗牌; 最后, 为了扩展用户兴趣点、引导用户选择, 将会人工地引入非相关商户/食物, 该部分将是我们后续优化点之一。下面将详细介绍“猜你喜欢”模块线上生效的部分洗牌逻辑,其他洗牌规则类似。
餐厅类目洗牌:
考虑到餐厅排序时, 为避免同类目餐厅扎堆问题, 我们设定了餐厅类目洗牌, 基本规则如下:
针对 top = SHOP_CATE_TOPNUM 餐厅, 不允许同类目餐厅连续超过 MAX_SHOP_SHOPCNT。
餐厅推荐食物数洗牌:
在餐厅列表排序时, 总是希望排在前面的商户具有更好的展示效果、更高的质量。针对 1*餐厅+3*食物 模式, 如果前排餐厅食物缺失(少于3个)时, 页面的整体效果就会大打折扣, 所以我们制定了食物数洗牌, 具体规则如下:
所有1个食物的餐厅沉底;
针对top=SHOP_FOODCNT_TOPNUM餐厅, 食物数 < SHOP_FOODCNT_FOODCNT(3) 的餐厅降权
餐厅名称洗牌:
正常时候, 推荐需要扩展和引导用户的兴趣点, 避免同类扎堆, 比如盖浇饭类目餐厅等。同样的, 我们也不希望相同或相似名称的餐厅扎堆, 比如连锁店、振鼎鸡等。针对此问题, 考虑到餐厅名称的不规则性, 我们通过分词和统计, 把所有餐厅名称做了结构化归类(distinct_flag), 比如所有“XXX黄焖鸡”都归为“黄焖鸡”、“星巴克 XX店”归为“星巴克”等。之后类似于餐厅类目洗牌, 做重排, 具体规则如下:
对top=SHOP_FLAG_TOPNUM 餐厅进行标签(flag)洗牌, 使得同一标签的餐厅排序位置差不得小于 SHOP_FLAG_SPAN
2、线上逻辑
从上一节中可知, 各个洗牌之间存在相互制约, 即洗牌不能并行、只能串行, 谁前谁后就会导致不同的排序结果, 所以, 这里需要考虑各个洗牌对排序的影响度和优先级:
-
影响度:即对原列表的重排力度, 比如对于连锁店少的区域, 名称洗牌的影响度就会小, 反之, 比如公司周边有25家振鼎鸡, 影响度就会变大;
-
优先级:即洗牌的重要性, 比如前排餐厅如果食物少于规定数量, 其实质是浪费了页面曝光机会, 所以食物数洗牌很有必要。
考虑到洗牌的串行逻辑, 越靠后的洗牌具有更高优先级。为了能够灵活变更线上的洗牌规则, 系统结合Huskar System(线上配置修改系统), 能够快速、便捷地更改洗牌逻辑,下面给出了一个配置实例。
[
{"name": "recfoods", "topnum": 15, "foodcnt": 3},
{"name": "category", "topnum": 15, "shopcnt": 2},
{"name": "shopflag", "topnum": 20, "span": 3, "exclude": "XXX"}},
{"name": "recfoods", "topnum": 15, "foodcnt": 3},
{"name": "dinner","topnum":5,"interval": ["10:30~12:30","16:30~18:30"]},
{"name": "mixture","topnum":12, "include": "XXX"}
]
四、总结
对于一个处于业务快速增长期的互联网企业,如何能够在最短时间内构建一个可快速迭代的推荐系统,是摆在眼前的现实问题。此次分享从饿了么自身业务出发,结合推荐系统的常见问题和解决方案,给出了从产品形态出发, 包括推荐模型与特征工程、日志处理与效果评估, 以及更深层次的场景选择和意图识别等在内多方面的线上实践,力图从整体及细节上还原和展示推荐系统的本质,以期能够为大家今后的工作提供帮助。
【CSDN_AI】热衷分享
博客地址:http://blog.yoqi.me/?p=2816
这篇文章还没有评论