时尚网站吉尔特(GILT)中的深度学习
作者: 保罗·卡雷·卡多纳(Pau Carré Cardona)
编译: AI100(公众号:rgznai100)
原文地址: http://tech.gilt.com/machine/learning,/deep/learning/2016/12/22/deep-learning-at-gilt
认知时尚领域的挑战
在时尚领域,有许多需要借助人类的认知能力才能完成的任务,比如分辨类似的产品或者从多个方面鉴定某种产品(如:连衣裙袖子的长度或轮廓类型)。
在吉尔特(GILT),我们正在建立起自动认知系统,通过这个自动认知系统检测连衣裙的轮廓、领口、袖子类型和适宜的场合。不仅如此,我们还在开发用于检测连衣裙相似点的新系统,用于产品推荐部分。此外,在与自动标记功能相结合的情况下,我们的用户将能找到与自己所搜索的产品相类似的结果,这些产品在某些方面会有所不同。例如,某个用户可能会对其中一款连衣裙十分感兴趣,但同时这位顾客又想要另一种类型的领口或者袖长。
对于上述提到的这些自动化认知任务,我们是利用深度学习的科技力量来实现的。最近,由于数学和算法的进步以及现代图形处理器(GPUs)海量并行处理的能力,深度学习在众多领域都取得了突破性的成果。
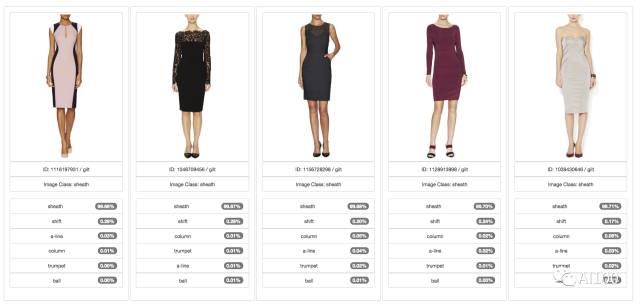
吉尔特(GILT)自动化裙子分类功能
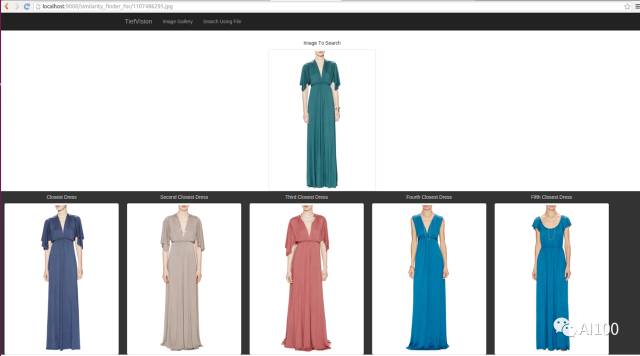
吉尔特(GILT)自动化查找类似连衣裙的功能
深度学习
深度学习的基础是深度神经网络。每一个神经网络都由一系列数值参数组成,这些参数负责将输入信息转化为输出信息。其中,输入的信息可以是图像中的原始像素,而输出的信息则有可能是与输入的图片相关的某种具体的产品(例如,一字型领口的连衣裙)。
为了实现上述目标,必须要在网络中设定正确的数值参数,以便系统做出准确的预测。这个实现的过程叫做神经网络训练,在大多数情况下均利用的是一种叫做“反向传播算法”(backpropagation)的基本算法,并根据需要对该算法进行变形。神经网络训练利用一组输入信息(例如:连衣裙的图像)和已知的我们称作训练集(training set)的目标输出信息(例如:某款可能的既定的连衣裙)来实现。反向传播算法利用训练集更新网络中的参数。输入图片信息之后,反向传播算法会对相应的参数进行提取,不断逼近目标信息。通过反向传播算法的多次迭代计算,最终建立目标模型。在输入既定的信息后,这个模型会输出非常接近搜索目标的信息。
神经网络训练一旦完成,如果模型的精确度很高而又没有受到过度拟合的影响,那么,不论何时在网络中输入何种新图片,预测的结果都应当是准确的。
例如,如果说我们要训练某个神经网络来检测领口的类型,我们需要利用一组已知领口类型的数据集信息。我们应当期待,如果网络中的参数设置无误的话,那么当我们向网络中输入胸前皱领的图片时,输出信息的相似度应当与胸前皱领这一目标信息接近100%。模型的精确性可以用一组输入信息通过计算而得出,也可以通过测试集(test set)计算得到。训练过程中不会使用测试集,因此,测试集能够客观地反映出网络对新数据的处理能力。
原子形式的神经网络是一个层状的结构。每一层都包含新的输入信息以及上一层的输出信息,通过这些参数计算得出新的输出信息,这些新的输出信息将作为输入信息而进入下一层。首层神经网络通常负责提取出图像的低级特征,例如衣服的边缘、拐角和线条等。深层神经网络将会负责提取图像较高层次的特征。其中,深层神经网络又包含许多层级,它们通常相互叠加在一起。
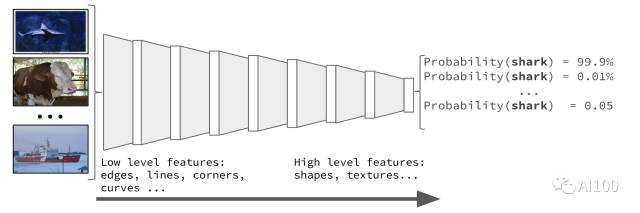
连衣裙分类
自动化裙子分类功能是吉尔特(GILT)正在开发的新功能之一。吉尔特(GILT)现在正在训练深层神经网络系统,以为裙子加上诸如“适用场合”、“轮廓大小”、“领口类型”以及“袖子类型”等标签。
连衣裙分类模型
用于训练的模型来自Facebook的开源软件项目Torch,而Torch是从微软ResNet的一种应用。Facebook 的项目实际上是一款图像分类器,其模型早已在ImageNet中接受过训练。我们只是在这个原始的开源软件项目中添加了一些新的特征:
- 挑选用作训练和测试的数据集(轮廓、场合、领口……)
- 计算不平衡数据集的加权损失
- 基于图像文件的路径进行推理
- 在AWS S3内或来源于AWS S3的存储和加载模型
- 随着新导入的数据集,自动同步图像标签
- 容许损坏或无效的图像
- 自定义标签的顺序
- 针对每一类进行 F1 得分精度计算,并且对每个图片的所有标签做出个人预测
- 为存在的网络添加空间变压器
这些模型在GPU P2 EC2实例中得到训练,利用Cloud Formation进行部署,并将EBS附加到模型上。我们打算用EFS来代替EBS,以使模型能够在不同的GPU实例中实现数据共享。
同时,我们也在借助TensorFlow和GoogleNet v3,努力实现将类似的结果归类的过程。
数据和质量管理
为了记录模型的结果,我们建立了一个Play web应用,以此分析模型的结果,保持数据集的持久稳固。与此同时,如果发现有错误的话,还可以改变样本的标签。
模型精度分析
分析机器学习结果的基础是F1 的得分,它能提供良好的度量标准,综合考虑到了假阳性和假阴性错误。
不仅如此,我们还提出了几个能够分析机器学习结果的观点,特别是在确保样本标记得当这一方面。

F1得分一览
图像标签的优化
精度分析使得我们能够检测出模型尽力想归类的图片。通常情况下,这些图片的标签都是错误的,必须手工重置标签。之后,需要用新的测试和新的训练集重新训练该模型。一旦模型得以重新训练,其精确性往往会有所提升,还有可能进一步地识别出标签错误的图片。
在这里需要注意的是,测试集中的图片必须始终处于测试过程中,而训练集中的图片必须始终处于训练过程中。只有在标签改变的情况下才可以例外,例如长袖的标签需要改变为带小外套的连衣裙。
为了升级系统,我们正在尝试利用亚马逊的机器人Turk,让重新贴标签的过程实现自动化操作。
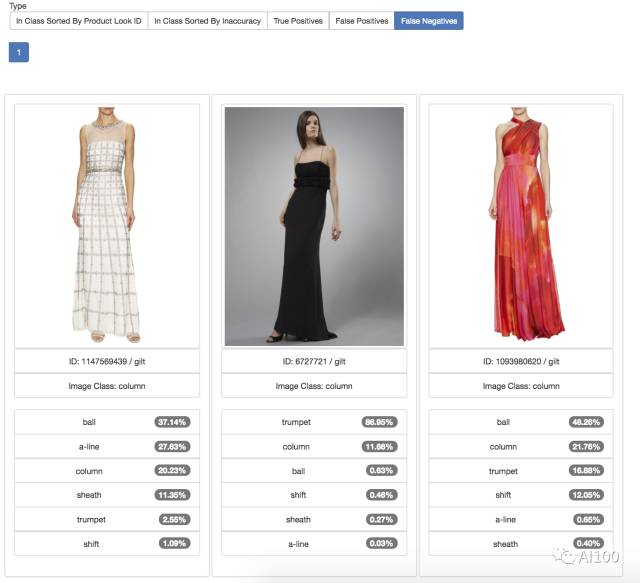
假阴性结果一览
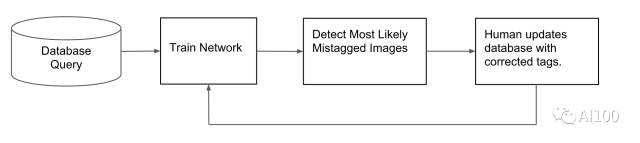
给图片贴标签的优化流程
备选方案软件即服务SaaS
备选方案是,让软件即服务SaaS公司为图片贴标签。我们已经在这方面做出了尝试,但是并没有取得成功。大多数这样的平台公司的问题是,在为时尚领域贴标签这方面,他们目前能够实现的精确度尚不理想,在细节方面也很难达到要求。
下面是利用亚马逊的Rekognition 为短袖连衣裙图片贴标签的结果:

连衣裙相似度
正是由于产品的相似度,我们才能为用户推荐类似的产品。同时,也正是由于产品的相似度,我们的顾客才能查找外表类似、某些方面不同的产品。
连衣裙相似度模型
在机器学习模型中,我们运用的是TiefVision。
TiefVision建立在对已经训练好的网络的重新利用基础之上,它将按照ImageNet数据集进行分类,在最后一层时与用作其他目的的新的网络进行交换。这项技术如今被称为迁移学习(transfer learning)。
根据计算机科学家扬·勒丘恩(Yann LeCun)的Overfeat算法,首先被训练的网络将用于定位图像中的连衣裙。这种定位算法将利用迁移学习的技术训练两种网络:
- 背景检测:检测连衣裙的背景和前景。
- 连衣裙定位网络:利用一小片连衣裙,定位图像中整个的连衣裙。
将连衣裙的定位功能和背景检测功能相结合准确地测定连衣裙的位置信息。
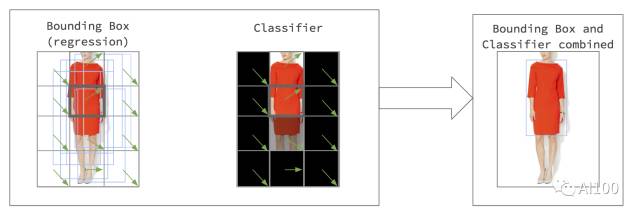
一旦定位到连衣裙,下一步的工作就是检测两件连衣裙是否相似。这一过程可以用非监督学习(unsupervised learning)的方法实现。另一种方法是,训练出一种能识别连衣裙相似性的网络,也就是监督学习(supervised learning)。
对于监督学习这种方法,我们采用的是谷歌的DeepRank算法。在输入三张图片的情况下,需要采用监督学习网络的方法,这三张图片分别是:参考性连衣裙、与参考性连衣裙类似的连衣裙、另一件与参考性连衣裙类似的连衣裙。利用Siamese网络,再运用铰链损失函数(Hinge loss function)训练网络,网络就能学会识别相似的连衣裙。
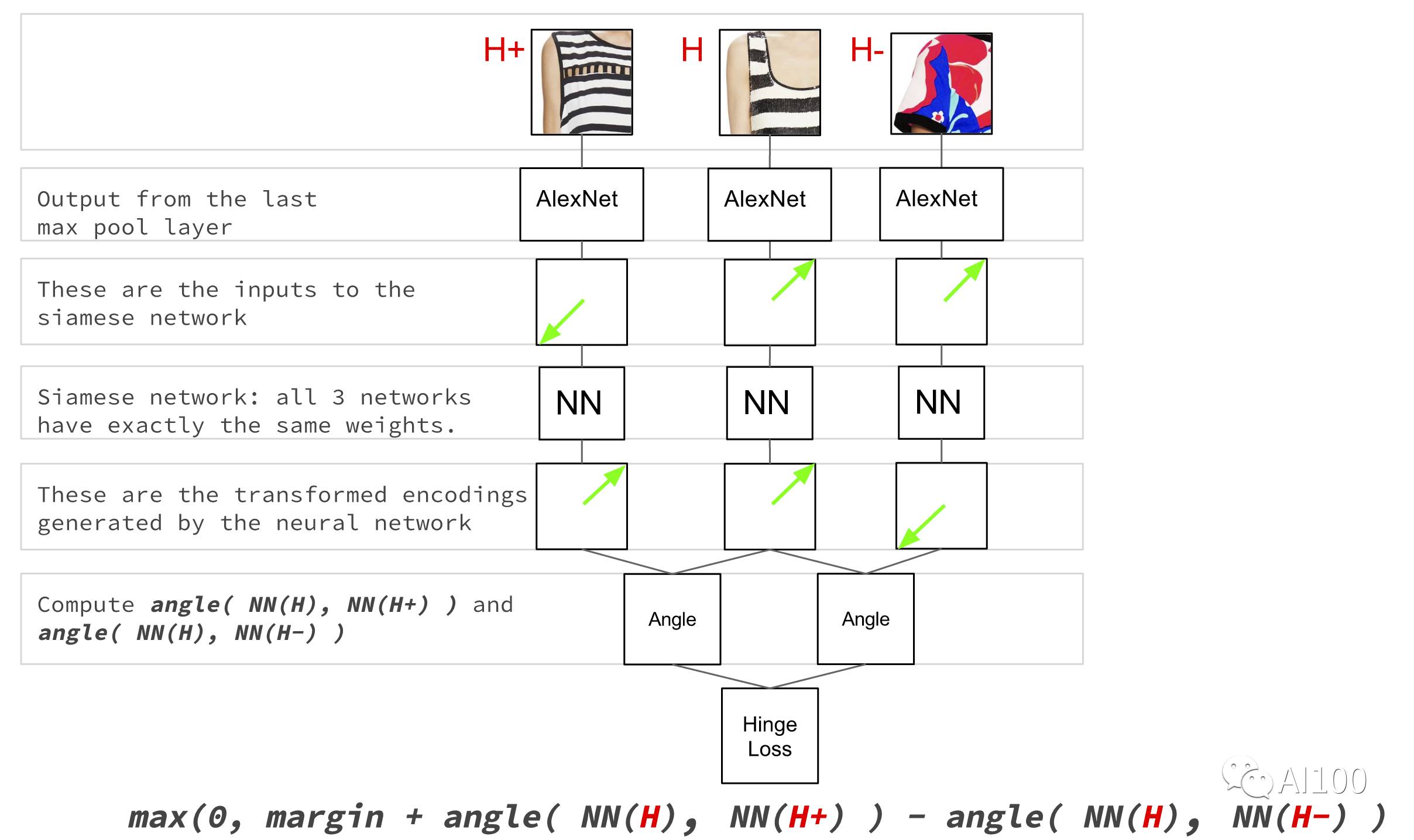
相似度网络拓扑
为了计算出数据库中某件连衣裙与另一件连衣裙的相似度,TiefVision需要进行下列两个步骤:
- 首先,运用位置和背景检测网络对连衣裙进行剪裁。
- 最后,利用连衣裙相似度网络计算出该剪裁后的连衣裙和原先数据库中的裁剪连衣裙的相似度。这种情况下,利用非监督学习的方法来计算相似度也是可以的。
----------
【CSDN_AI】热衷分享
博客地址:http://blog.yoqi.me/?p=2807
这篇文章还没有评论