使用SMACK堆栈进行快速数据分析
作者:马小龙,浙江财经大学数据分析和大数据计算的客座教授。2006年在德国不来梅大学获得数学博士学位后,在多特蒙德大学软件工程研究所从事研究和教学工作直到2011年来到中国。
本文为《程序员》原创文章,未经允许不得转载,更多精彩文章请订阅《程序员》
从大数据到快速数据
除了能够以批处理模式分析大型数据集之外,现代数据驱动型组织还需要尽快从所收集的数据中生成洞察,并最终采取行动。在这方面,传统的Hadoop堆栈(HDFS作为存储层,MapReduce或Tez作为处理框架,YARN作为集群资源管理器)缺乏严重性。为了减轻这种情况,业界已经提出了诸如Lambda架构(见《程序员》2016年11月“Lambda与Kappa计算架构之我见”一文)等架构。在Lambda架构中,一个“慢”大数据处理框架(如Hadoop堆栈)与一个“快速”的流处理框架(如Apache Storm)组合在一起。由快速框架处理的数据或者与慢速处理框架周期性地重新集成,或者完全丢弃,并且由使用慢速处理框架处理的数据代替。当然,这种Lambda型结构并不是没有问题,它会导致代码重复和需要重新处理与集成数据。
SMACK堆栈
所谓的SMACK堆栈是一个在过去一年中变得流行的架构。SMACK堆栈的各部分如下:
-
Spark作为一个通用、快速、内存中的大数据处理引擎;
-
Mesos作为集群资源管理器;
-
Akka作为一个基于Scala的框架,允许我们开发容错、分布式、并发应用程序;
-
Cassandra作为一个分布式、高可用性存储层;
-
Kafka作为分布式消息代理/日志。
首先我们将快速讨论组成SMACK堆栈的部件,特别注意Cassandra,因为它与堆栈的其他部分不同,似乎没有在国内广泛使用。
Apache Spark
Apache Spark已经成为一种“大数据操作系统”。数据被加载并保存到簇存储器中,并且可以被重复查询。这使得Spark对机器学习算法特别有效。Spark为批处理、流式处理(以微批处理方式)、图形分析和机器学习任务提供统一的接口。它用Scala编写,并公开了Scala、Java、Python和R的API。此外,Spark能够对数据执行SQL查询,更利于分析师们学习传统的BI工具。
Apache Mesos
Apache Mesos是一个开源的集群管理器,由加州大学伯克利分校开发。它允许跨分布式应用程序的高效资源隔离和共享。在Mesos中,这样的分布式应用程序被称为框架。
Akka
Akka是构建在JVM上运行的并发程序框架。强调一个基于actor的并发方法:actors被当作原语,它们只通过消息而不涉及共享内存进行通信。响应消息,actors可以创建新的actors或发送其他消息。actor模型由Erlang编程语言编写,更易普及。
Apache Cassandra
Cassandra最初是在Facebook开发的,后来成为一个Apache开源项目。它是一个分布式、面向列的NoSQL数据存储,类似于Amazon的Dynamo和Google的BigTable。与其他NoSQL数据存储相反,它不依赖于HDFS作为底层文件系统,具有无主控架构,允许它具有几乎线性的可扩展性,并且易于设置和维护。Cassandra的另一个优势是支持跨数据中心复制(XDCR)。跨数据中心复制实际上有助于使用单独的工作负载和分析集群。Cassandra的企业版可从DataStax (http://www.datastax.com)获得。
根据固定分区键,数据在Cassandra集群的节点上分割。其架构意味着它没有单点故障。根据CAP定理,我们可以在每个表的基础上对一致性和可用性进行微调。
Apache Kafka
在SMACK堆栈内,Kafka负责事件传输。Kafka集群在SMACK堆栈中充当消息主干,可以跨集群复制消息,并将其永久保存到磁盘以防止数据丢失。
在详细了解SMACK堆栈的各部分如何协同工作之前,我们将快速讨论Cassandra的数据模型及其在Cassandra上进行分析所面临的挑战。
Cassandra数据模型
与其他NoSQL数据存储类似,基于Cassandra应用程序的成功数据模型应该遵循“存储你查询的内容”模式。也就是说,与关系数据库相反,在关系数据库中,我们可以以标准化形式存储数据。当我们谈论Cassandra数据模型时,仍然使用术语table,但是Cassandra表的行为更像排序,分布式映射,然后是关系数据库中的表。
Cassandra支持用于定义表与插入和查询数据的SQL语言,称为Cassandra Query Language(CQL)。
当定义一个Cassandra表时,我们需要提供一个分区键,它确定数据在集群节点之间的分布方式,以及确定数据如何排序的聚簇列。当使用CQL查询时,我们只能查询(使用WHERE子句)并根据聚簇列排序。
让我们来看看Cassandra文档中的一个示例,该文档是音乐共享服务(如Spotify)中的播放列表建模:

在这个例子中,uuid(通用唯一ID,保证在多个机器之间是唯一的)id是分区键,song_order是聚类列,(id,song_order)需要在表的所有行中都是唯一的。此外,id决定了在哪个机器上存储行,song_order决定了行在物理主机上的存储顺序。也可以在Cassandra中使用复合分区键,将它们放在()中。
CQL查询如下所示:
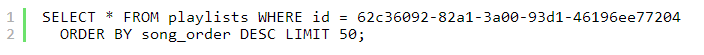
WHERE子句中出现的任何列都要求是主键的一部分,或者可以在其上定义索引。此外,分区键只能出现在相等(=)操作中。只有当所选行的集合被作为连续块存储在主机上时,范围查询才是可行的。通过聚类SQL的类似列和LIMIT子句,CQL能够支持排序,但不具备GROUP BY的类似功能。
根据特定列进行查询,减少了对随机磁盘访问的需求,但也强烈限制了Cassandra作为分析数据库的使用。“存储你查询的内容”范例需要根据Cassandra数据库上执行的查询进行仔细地数据建模,从而限制了支持新查询的能力。为了对存储在Cassandra中的数据执行分析,应该将数据加载到单独的处理框架中,我们选择Apache Spark框架。

图1 操作集群和带有并置的Spark节点的单独的分析集群
连接Spark和Cassandra
Spark-Cassandra连接器(https://github.com/datastax/spark-cassandra-connector)可以把Cassandra表作为Spark RDDs,将Spark RDDs写入Cassandra表,以及在Spark应用程序中执行任意CQL查询。如果可以,还应使用CQL WHERE子句将筛选操作下推到服务器端节点。
为了最大化利用Spark-Cassandra连接器的数据位置感知功能,集群的Spark和Cassandra节点应并置。Cassandra的XDCR跨数据中心复制实际上允许我们分离出一个分析集群,一个Spark节点与Cassandra节点并置,一个Cassandra集群用于重写操作,其内容被自动复制到分析集群。这样,任何沉重的分析操作都不会影响纯Cassandra集群的写入性能。将操作(写入繁重)集群与分析集群分离可提供以下额外的好处:
-
两个集群可以独立缩放;
-
由于分析和操作集群具有不同的读/写模式,可以优化每个集群以实现其预期用途;
-
Cassandra自动处理数据复制;
-
仅需要将其他信息(例如要与其连接的查找表)存储在分析集群上。
Mesos架构
Mesos从头开始设计,用于处理异常繁杂的工作负载,也就是说可以将长期运行的批处理作业与较短的事件处理类型任务组合在一起。
Mesos集群由两种类型的节点组成:
-
主节点,负责资源提供和调度;
-
从节点,运行实际任务。
主节点也可以复制,以提供高可用性。在这种情况下,Zookeeper可以用于领导选举和服务发现。使用Mesos执行任务的过程遵循以下步骤:
-
从节点向主节点发布可用资源;
-
主节点发送资源到框架(App);
-
框架中的调度程序回复需要被调度的任务;
-
任务由主机发送到从机。
两个工具帮助我们使用Mesos计划作业:Marathon旨在安排长时间运行的任务;Chronos的行为就像一个“分布式cron”,重复执行短时间运行的任务。我们可以用以下方式部署Spark/Mesos/ Cassandra集群:
-
Mesos主节点与Zookeeper节点并置;
-
Cassandra节点与Spark执行器节点并置。

图2 Cassandra和Spark的Mesos部署方案
使用Akka进行数据摄取
选择合适的存储层后,现在需要决定如何处理传入数据。对数据摄取层的要求是:
-
低延迟和高吞吐量
-
弹性
-
可扩展性
-
背压手柄负载尖峰
actor完全满足前三点,例如从HTTP请求中处理每个传入事件并将其存储在Cassandra中。
使用Kafka进行预处理
Akka无状态设计的一个缺点是:actor不能执行任何的数据预处理。Cassandra同样不适合。使用Spark或Spark Streaming执行这种预聚合也不理想,因为Spark Streaming的微批处理架构并不适用于快速事件处理。
Apache Kafka是合适的备选。因此在SMACK堆栈中,Akka actors将预处理数据写入分布式日志,如Apache Kafka。为了从Kafka读取数据,可以依靠Spark Streaming,使用Spark Streaming可以将数据备份到HDFS或对象存储(如Amazon S3或阿里云OSS),同时将其写入Cassandra群集。这充当了有效的备份机制,并且根据用例,OSS/S3的存储成本可能远低于在Kafka集群中保留数据。然后可以使用Spark从对象存储中恢复数据。在对象存储中非现场存储数据还可防止任何数据中心级故障对组织数据带来严重影响。
结论
SMACK堆栈具有以下优点:
-
简单工具箱,支持各种数据处理任务(流式、批处理、Lambda类型的架构);
-
依靠经过测试的开源框架;
-
统一集群管理;
-
易于扩展和复制。

图3 SMACK堆栈架构概述
此外,应用程序中必须写入特定代码的主要组件(Akka、Kafka、Spark)都可以使用Scala进行编程,从而允许在架构的不同部分有效共享业务逻辑类型的代码。
博客地址:http://blog.yoqi.me/?p=2804
这篇文章还没有评论