文本情感分类(一):传统模型
前言
作者在去参加了两个数据挖掘相关的竞赛,分别是物电学院举办的“亮剑杯”,以及第三届 “泰迪杯”全国大学生数据挖掘竞赛。很碰巧的是,两个比赛中,都有一题主要涉及到中文情感分类工作。经过这两次的竞赛,我已经基本了解深度学习的思想,并且用深度学习的算法实现了文本情感分类模型。因此,作者打算将两个不同的模型分享给大家,供读者参考。刚入门的读者,可以从中比较两者的不同,并且了解相关思路。高手请一笑置之。
基于情感词典的文本情感分类


传统的基于情感词典的文本情感分类,是对人的记忆和判断思维的最简单的模拟,如上图。我们首先通过学习来记忆一些基本词汇,如否定词语有“不”,积极词语有“喜欢”、“爱”,消极词语有“讨厌”、“恨”等,从而在大脑中形成一个基本的语料库。然后,我们再对输入的句子进行最直接的拆分,看看我们所记忆的词汇表中是否存在相应的词语,然后根据这个词语的类别来判断情感,比如“我喜欢数学”,“喜欢”这个词在我们所记忆的积极词汇表中,所以我们判断它具有积极的情感。
基于上述思路,我们可以通过以下几个步骤实现基于情感词典的文本情感分类:预处理、分词、训练情感词典、判断,整个过程可以如下图所示。而检验模型用到的原材料,包括薛云老师提供的蒙牛牛奶的评论,以及从网络购买的某款手机的评论数据。

文本的预处理
由网络爬虫等工具爬取到的原始语料,通常都会带有我们不需要的信息,比如额外的Html标签,所以需要对语料进行预处理。由薛云老师提供的蒙牛牛奶评论也不例外。我们队伍使用Python作为我们的预处理工具,其中的用到的库有Numpy和Pandas,而主要的文本工具为正则表达式。经过预处理,原始语料规范为如下表,其中我们用-1标注消极情感评论,1标记积极情感评论。

句子自动分词
为了判断句子中是否存在情感词典中相应的词语,我们需要把句子准确切割为一个个词语,即句子的自动分词。我们对比了现有的分词工具,综合考虑了分词的准确性和在Python平台的易用性,最终选择了“结巴中文分词”作为我们的分词工具。
下表仅展示各常见的分词工具对其中一个典型的测试句子的分词效果:
测试句子:工信处女干事每月经过下属科室都要亲口交代24口交换机等技术性器件的安装工作

载入情感词典
一般来说,词典是文本挖掘最核心的部分,对于文本感情分类也不例外。情感词典分为四个部分:积极情感词典、消极情感词典、否定词典以及程度副词词典。为了得到更加完整的情感词典,我们从网络上收集了若干个情感词典,并且对它们进行了整合去重,同时对部分词语进行了调整,以达到尽可能高的准确率。

我们队伍并非单纯对网络收集而来的词典进行整合,而且还有针对性和目的性地对词典进行了去杂、更新。特别地,我们加入了某些行业词汇,以增加分类中的命中率。不同行业某些词语的词频会有比较大的差别,而这些词有可能是情感分类的关键词之一。比如,薛云老师提供的评论数据是有关蒙牛牛奶的,也就是饮食行业的;而在饮食行业中,“吃”和“喝”这两个词出现的频率会相当高,而且通常是对饮食的正面评价,而“不吃”或者“不喝”通常意味着对饮食的否定评价,而在其他行业或领域中,这几个词语则没有明显情感倾向。另外一个例子是手机行业的,比如“这手机很耐摔啊,还防水”,“耐摔”、“防水”就是在手机这个领域有积极情绪的词。因此,有必要将这些因素考虑进模型之中。
文本情感分类
基于情感词典的文本情感分类规则比较机械化。简单起见,我们将每个积极情感词语赋予权重1,将每个消极情感词语赋予权重-1,并且假设情感值满足线性叠加原理;然后我们将句子进行分词,如果句子分词后的词语向量包含相应的词语,就加上向前的权值,其中,否定词和程度副词会有特殊的判别规则,否定词会导致权值反号,而程度副词则让权值加倍。最后,根据总权值的正负性来判断句子的情感。基本的算法如图。
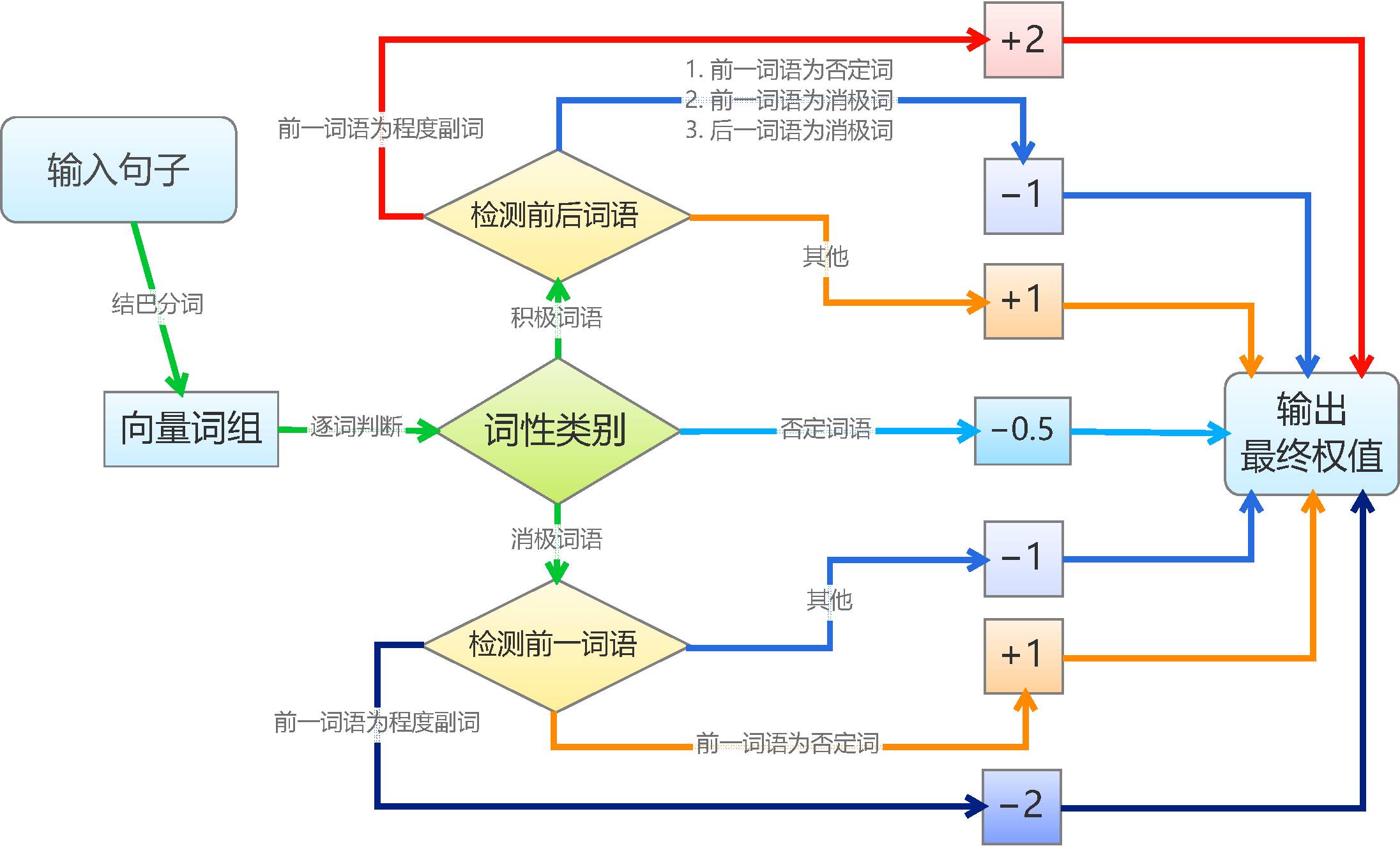
要说明的是,为了编程和测试的可行性,我们作了几个假设(简化)。假设一:我们假设了所有积极词语、消极词语的权重都是相等的,这只是在简单的判断情况下成立,更精准的分类显然不成立的,比如“恨”要比“讨厌”来得严重;修正这个缺陷的方法是给每个词语赋予不同的权值,我们将在本文的第二部分探讨权值的赋予思路。假设二:我们假设了权值是线性叠加的,这在多数情况下都会成立,而在本文的第二部分中,我们会探讨非线性的引入,以增强准确性。假设三:对于否定词和程度副词的处理,我们仅仅是作了简单的取反和加倍,而事实上,各个否定词和程度副词的权值也是不一样的,比如“非常喜欢”显然比“挺喜欢”程度深,但我们对此并没有区分。
在算法的实现上,我们则选用了Python作为实现平台。可以看到,借助于Python丰富的扩展支持,我们仅用了一百行不到的代码,就实现了以上所有步骤,得到了一个有效的情感分类算法,这充分体现了Python的简洁。下面将检验我们算法的有效性。
模型结果检验

作为最基本的检验,我们首先将我们的模型运用于薛云老师提供的蒙牛牛奶评论中,结果是让人满意的,达到了82.02%的正确率,详细的检验报告如下表

其中,正样本为积极情感评论,负样本为消极情感数据,
准确率 = 被正确判断的样本数 / 总样本数
真正率 = 被判断为积极的正样本数 / 正样本总数
真负率 = 被判断为消极的负样本数 / 负样本总数
让我们惊喜的是,将从蒙牛牛奶评论数据中调整出来的模型,直接应用到某款手机的评论数据的情感分类中,也达到了81.96%准确率!这表明我们的模型具有较好的强健性,能在不同行业的评论数据的情感分类中都有不错的表现。

结论
我们队伍初步实现了基于情感词典的文本情感分类,测试结果表明,通过简单的判断规则就能够使这一算法具有不错的准确率,同时具有较好的强健性。一般认为,正确率达80%以上的模型具有一定的生产价值,能适用于工业环境。显然,我们的模型已经初步达到了这个标准。
博客地址:http://blog.yoqi.me/?p=1225
这篇文章还没有评论