去哪儿网基于Marathon管理Spark 2.0实现动态扩容实践
作者丨李雪岩、徐磊、吕晓旭
责编丨魏伟
去年10月,我们实现了Spark 1.5.2版本运行在Mesos这个资源管理框架上。随后Spark出了新版本我们又对Spark进行了小升级,升级并没有什么太大的难度,沿用之前的修改过的代码重新编译,替换一下包,把历史任务全部发一遍就能很好的升级到1.6.1也就是现在集群的版本,1.6.2并没有升级因为感觉改动不是很大。到现在正好一年的时间,线上已经注册了44 个Spark任务,其中28个为Streaming任务,在运行这些任务的过程中,我们遇到了很多问题,其中最大的问题是动态扩容问题,即当业务线增加更复杂的代码逻辑或者业务的增长导致处理量上升的时候会使Spark因计算资源不足,这时候如果没有做流量控制则Spark任务会因内存承受不了而失败,如果做了流量控制则Kafka的lag会有堆积,这时候一般就需要增加更多的executor来处理,但是增加多少合适一般不太好判断,于是要反复地修改配置重新发布来找到一个合理的配置。
我们在Marathon上使用Logstash的时候也有类似的问题,当由于接入一个比较大的日志导致流量突然增加使得Logstash处理不了时,Kafka的Lag产生堆积,这时我们只需直接上Marathon的界面上点Scale然后填入更大的实例数字就能启动了一些Logstash实例自动平衡地去处理了。当发现某个结点是慢结点不干活的时候,只需要在Marathon上将对应的任务Kill掉就会自动再发一个任务替补他的位置,那么Logstash既然都可以做到为什么Spark不可以?因此我们决定在Spark 2.0版本的时候来实现这个功能,同时我们也会改进其它的一些问题,另外Spark2.0是一个比较大的版本升级,配置与之前的1.6.1不同,不能做到直接全部重发一遍任务来做到全部升级。
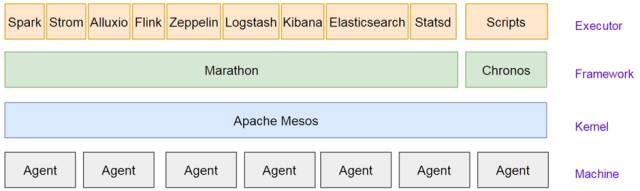
在这里我们首先介绍一些Mesos的一些相关概念,Mesos的Framework是资源分配与调度的发起者,Spark自带了一个spark-mesos-dispacher的Framework用来管理Spark的资源调度。而Marathon也是一个Framework他的本质和mesos-dispacher或spark schedular相同。
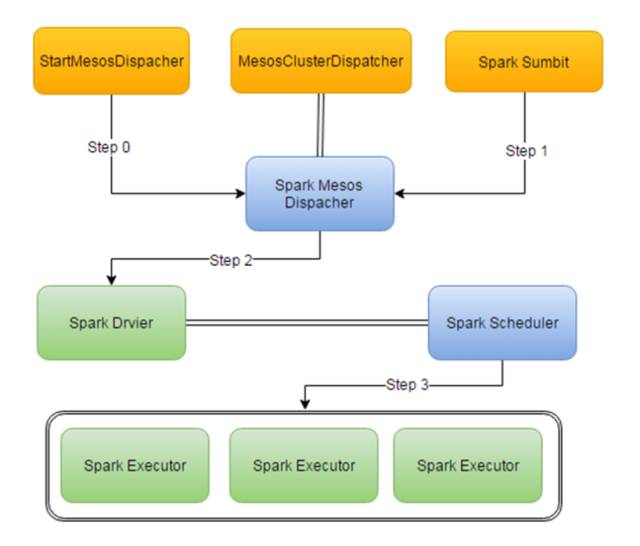
在图2在这个架构中,你首先得向mesos注册一个mesos-dispacher的Framework,然后,通过spark-sumbit脚本来向mesos-dispacher发布任务,mesos-dispacher接到任务以后开始调度他负责发一个Spark Driver,然后driver在mesos模式下,他会再次向mesos注册这个任务的Framework也就是我们看到的Spark UI,也可以理解为他自己也是个调度器,然后这个Framework根据配置来向Mesos申请资源来发一些Spark Executor。
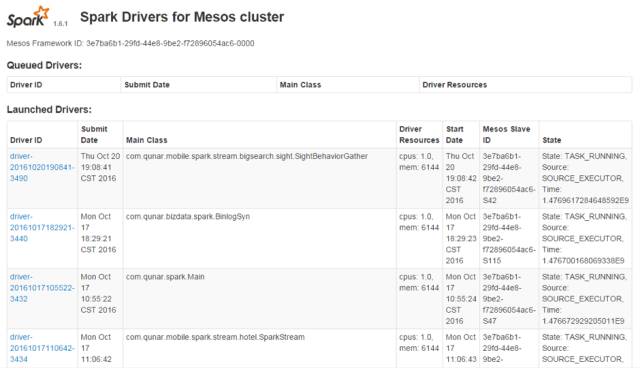
从图3可以看出,mesos-dispacher只提供了下功能:
-
他只提供了一个配置查看的界面,可以看到资源分配的信息,点进去以后可以看到SparkConf的一些参数,但是这个我们在业务线发布的时候已经拿到了这些配置,在这里只能确认下Driver是否配置正确,并且在SparkUI上也能看到。
-
他自带一个Driver队列,他会按顺序依次发布,当资源不足时会在队列里等待。
-
他自带一个Driver的HA功能,但是当你提交Driver代码有问题,他会不断地反复重发,比较难杀掉,但也是能杀掉的,并且没有次数限制。所以我们一般也不开放这个功能。
所以mesos-dispacher并不是一个完备的Framework,在我们使用的过程中发现了存在以下的问题:
-
在我们发布Spark的时候需要向mesos-dispacher提供一个SPARK_EXECUTOR_URI的配置来提供SPARK运行环境的地址,一开始我们是使用http的方式来放环境的,但是在一次需要发60个executor的时候流量打满了,原因是我们编译出来的Spark的环境包大概250MB,在发布的时候60台机器同时拉取这个环境就把流量打爆了。因此我们的解决方案就是在每一台机器上都部署Spark的环境,把SPARK_EXECUTOR_URI设成本地目录来解决这个问题。
-
界面上的配置并不会真正地同步到driver或executor。由于SPARK的配置很灵活,你的mesos-dispacher启动的时候会读取spark-defalut.conf来加载配置,每次发布时他又会从spark-env.conf里读取配置,发driver的时候,driver又会从他的jar包里的配置读取配置,用户自己也可以设置sparkConf的配置,executor的jar包里同样也有配置,最终你会发现有些配置设了生效了,有些配置的设置他没有传递,从而造成配置混乱。
-
mesos-dispacher基本功能缺失。mesos-dispacher虽然是专门为mesos设计的,但是他对mesos的基本功能,如role和constrain支持都不好,如果不修改代码是无法支持role和constrain,关于这个我提交了个一PR并且在Spark2.0已经没有这个问题了。
mesos-dispacher并不能运行时修改配置,必须重启。比如我们上了一些新机器,打了其它一些标签或者是多标签,如果想使其生效必须停止mesos-dispacher再启动才能生效,无法在运行时修改。mesos-dispacher默认工作在非HA模式下,因此在启动mesos-dispacher在的时候一定要加上Mesosr的zk这样当停止了mesos-dispacher以后,在mesos-dispacher上的任务将不会受到影响,当重新启动mesos-dispacher的时候会自动接管任务。 -
没有动态扩容功能。我们希望做到的就是可以让Spark可以在运行时增加实例或减少,但是受于架构限制mesos-dispacher只能管理driver,如果改mesos-dispacher的代码的话只能实现动态扩driver没有意义。
-
此外也有另一种方案就是帮助Spark改进他的Framework使他更强大,但是我们发现只需要Marathon这一个优秀的Framework就可以了,重复造轮子的成本比较大。同时也不希望对Spark代码有过多的修改,这样不利于升级。
由于mesos发布有很多种模式,我们在做这个时候主要考察了2种模式。
独立集群模式
该模式需要启动一个master作为发布的入口,再对每个实例分别启动slave。这时候每个slave在启动的时候资源已经固定了。再增加资源的时候需要启动新的slave然后停止之前的任务修改资源配置数重发,这种模式的好处是有一个单独的界面,你可以直接给业务线这个独立集群模式的界面来用,界面上他们可以根据自己固定的资源发多个任务,并且在SparkUI上可以直接看到日志。另外它是预先占资源模式,在发布时不会有资源争抢导致资源不够的情况,但是缺点就是做不到运行时的动态扩容。
仿mesos-dispacher模式
该模式下,我们使用Marathon这个framework来模仿mesos-dispacher所做的事,就是先发一个driver然后再发executor挂载到driver来执行任务。关于日志,我们还是使用之前的方式调用Mesos的接口来获得日志。当需要增加资源的时候直接往结点继续挂executor就可以,当需要删除结点的时候直接停止executor即可。
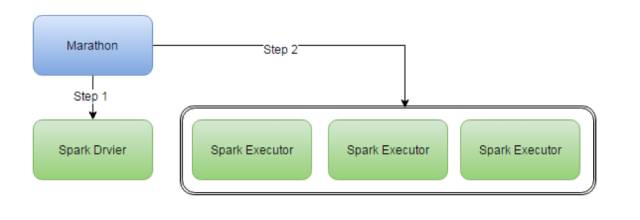
如何实现仿mesos-dispacher模式
我们要做的事实际上是把图2的架构图变成图4的模式,其中Step 1和Step 2需要模仿,而Step 0则不需要,因为Step 0只是启动Framework的。我们通过观察meos-dispacher发现Step 1所做的实际上是调用Spark Submit向Mesos注册一个Framework然后再由driver来负责调度,我们利用mesos的constraints的特性,设置一个不存在的不可调度的策略,例如:colo:none,这样一来driver就无法管理资源,而我们使用Marathon自己来发布Spark Executor来挂到driver上来实现Marathon控制Spark的资源调度策略。由于Mesos他是把Offer推送给Framework的这一特性,我们使用的这种方式也不会有性能问题。

那么图2中的Step 2是如何做到的呢?我们通过分析Spark源代码发现,Spark 2.0.2在Executor挂到drvier上是通过图5的命令来做到的。所以通过Marathon发布Spark Executor的基本原理就是模仿上面的图5代码。
从图6可以看出Marathon发布的时候先发Spark Driver拿到mesos分配的Spark Driver的IP和PORT填入脚本,这个参数是Driver与Executor之间通信的通道,在发Spark Executor的时候需要提供,这个Driver的IP我们通过Mesos接口可以拿到,因为Driver会向Mesos注册一个Framework,我们拿到Framework的信息就拿到了IP和PORT,同时我们还可以拿到FrameworkID那这个PORT是在制作Docker镜像的时候随机分配的一个PORT0的一个环境变量,然后通过spark.driver.port指定,这样Executor这端就可以调用Marathon的REST API来拿到driver的Port。
而参数executor-id是Spark Driver调度时按顺序分配的ID,从0开始每次递增1,如何生成executor-id呢?这个由Spark Executor自己生成一个不超过int的范围的不重复的随机数即可,这个的ID的不会影响其它行为。hostname可以直接通过命令获取。cores是我们通过用户提交的配置来计算出来的,这个Core需要填spark.executor.cores也就是每个Spark Executor的正常使用的Core与spark.mesos.extra.cores分配给每个Spark Executor之和。
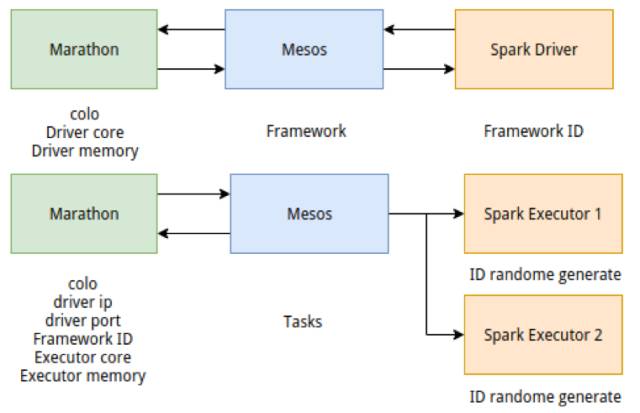
最后一项目app-id通过研究发现在Mesos上实际上就是Framework ID直接通过Mesos接口就可以获得。这样我们就完成了Executor的发布,通过拼上述的命令来把Spark Executor挂到了Driver上,但是实际生产应用中,我们发现了,他还存在Driver和Executor的同步问题。
Spark Receiver的平衡问题
这里介绍一下在Kafka使用了高阶API时,影响Spark性能的Receiver平衡问题,使用低阶API则不会有这个问题。如果使用Spark提供的Kafka高阶API,你会在代码里预先指定好Receiver的数量,然后再做一个Union,在Spark代码中他实际上是这样做的,他会先等待Executor连上Driver,默认是30s如果超过了调度的时间则开始进行Receiver的调度,而调度策略是ReceiverPolicy类里写死的,ReceiverPolicy的调度策略可以概括为,尽量保证均匀的分配给每个Host一定量的Recevier。
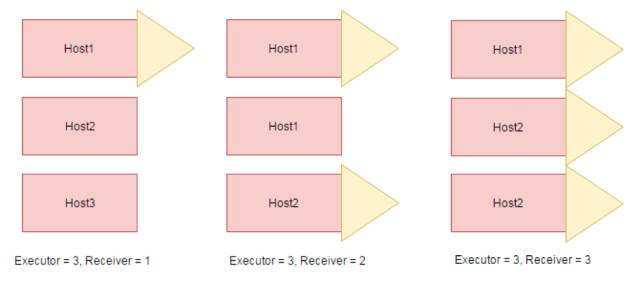
举个例子来说,如图7当你启动了3个Spark Executor时,如果代码里指定了启动1个Executor,如果每个Executor启动在了不同的Host下,Spark在Receiver调度开始时随机地指定一个Executor启动Receiver并分配1个Core给这个Task。但是如果代码里指定为2个Receiver而2个Executor启动在了同1个Host1上,另一个启动在了Host2上,也就是Receiver的数量等于Host Unique数量,则他会在Host1中保证其中的一个Executor启动1个Receiver,Host2中启动一个Receiver。如果Receiver的数量,大于了Host Unique的数量如第三张图,则他会在随机地在Host1或者Host2中开Receiver,这就带来了一个问题。分析Spark源代码可知Spark Driver和Spark Executor之间通过运行一个DummyJob,也就是一个MapReduce任务来保证他们之间的同步的,但是他这种做法只能保证一个Spark Executor挂在了Spark Driver上,而不能够保证所有的Executor比如当只有一个Spark Executor挂在Spark Driver上的时候,这时候开始Receiver开始调度。
如何保证Driver和Executor之间同步
读过Spark官方文档的朋友都知道,Spark提供了2个参数去解决这个问题,他们分别是spark.scheduler.maxRegisteredResourcesWaitingTime用来设置一个等待Executor挂上的时间和spark.scheduler.minRegisteredResourcesRatio用来检查资源分配的比例,但是使用我们这种方式这两个参数都不起作用了,因为Spark在实现的过程中是通过一个运行一个DummyJob来保证这种挂载的方式同步的,这也是为什么第一个任务一定是70个Task的原因,但是他这种方式只能保证一个Executor挂上去了以后才开始调度Recevier,因此我们对源代码进行了修改,主要是ReceiverTracker那部分通过我们自定义的一个配置,让Executor数量达到指定的个数以后才开始发布,这样在Receiver调度的时候才会保证能够均匀地分配在各个结点,从而实现最好的性能。另外对于业务线写的jar包,我们是要求打成assembly包然后提交到我们的发布系统,发布系统会上传到swift上,在发布的时候,我们会先在容器里把包下载下来,然后启动Spark Driver,而当Spark Executor挂在Spark Driver上的时候,他们会自动从Spark Driver获取对应的jar包。
如何保证容器的时间和编码的准确性让配置同步
之前在部署1.6.1的mesos-dispacher架构的时候,我们就已经发现, Spark打出的中文日志会产生乱码,然后我们做了各种实验发现,无论如何设置JVM参数,或是使用代码进行内部的转换都解决不了乱码问题,在新架构的Docker环境中也不例外,不过最终还是让我们解决了,我们发现通过设置JAVA_TOOL_OPTIONS这个环境变量,JAVA虚拟机的参数才真正的修改生效,于是我们在容器启动的时候配置了file.encoding=UTF-8,乱码问题得才以解决,除此之外在Docker镜像中系统的时间也是不准确的,默认是UTC时间,而系统时间对代码的影响也很大,有可能写入到HDFS的文件是以时间戳生成的,我们一开始解决这个问题的方法是通过以只读的方式在Docker中挂载宿主机上的/etc/localtime来修正时间,但是发现时间还是不正确,这时因为Spark内部还会根据时区自动修正时间为UTC,所以还需要给JVM加一个环境变量设置user.timezone=PRC 这样时间才可以保证时间是对的,另外使用这种架构的时候spark.driver.extraJavaOptions和spark.executor.extraJavaOptions这两个参数也不会生效,需要用户通过发布配置传过来,然后在容器中追加到JAVA_TOOL_OPTIONS。另外值得注意的是SPARK_EXECUTOR_MEMORY也不会同步,需要手动来进行设置。
如何保证driver和executor失败时同步
虽然我们之前解决了marathon发布driver和executor之间的连接问题,但是由于mesos接口慢,在我们实际测试中,发30个executor就可以把mesos打挂,因此,我们想了另一个办法来解决这个问题,我们首先修改了Spark代码,让他的Spark Driver在不依赖mesos-dispacher的情况下实现driver的HA,HA的实现原理大概就是每次在Spark Driver启动注册Framework的时候,把Framework ID存到zk里,然后在程序挂掉了以后保持Framework与Mesos的连接,在下次启动的时候重新注册这个Framework,这样的话,Framework ID可以基本保持不变,在发布Spark Executor的时候就可以固定住这个Framework ID在Executor挂掉的时候marathon拉起来也能保证重连,而driver如果挂掉的话,他会重新注册,获得的Framework ID不变,又可以继续运行,这样做只需要在Spark Driver发布完成以后调用一次Mesos接口拿到Framework ID分发给Spark Executor就可以了。顺便说一下Spark Executor拿Spark Driver的ip和port是通过调Marathon接口实现了,而Marathon接口速度很快,不会有这个问题。
如何升级Spark版本
对于业务线的任务来说升级Spark是一件比较麻烦的事,主要原因是需要他们改代码,不过从改代码的角度来说,变化也不算大,也就是Spark版本和Scala版本变一下,另外就是有些API也需要做一点调整,另外就是升级麻烦的另一个原因也是因为之前没有使用Marathon+Docker的模式,如果之前就使用了这种模式,那只需要把镜像给修改了,愿意升级的升级,不愿意升级的可以使用原来的镜像跑,在以后的升级中,我们只需要制作新镜像就可以了,非常方便迁移,可以让他跑在任何集群。那现在为了过渡到这种模式,再结合之前发布的经验,我们使用的模式是旧的有一套配置,新的也有一套配置,然后通过在git上打tag的方式,在旧的配置里加入升级信息,然后发布逻辑改为优先读取是否要升级,如果需要升级则发在新集群上,如果不需要则保持原来不变,我们会先让业务线进行测试,同时保持旧的任务在线,当他们测试通过了以后,再停止旧的作务,把改好的新版本发到新集群上,当发现有问题的时候可以用原来的tag进行回滚,因为原来的tag里的配置会先判断是否需要升级,而之前的配置肯定没有需要升级的选项。
如何监控Spark的运行状态
Spark自身有一套metric监控,这个在新版本也不例外,在我们集群中唯一的变更就是把不靠谱的udp改成了tcp,另外我们因为使用的是Docker容器,这样我们就还有另一套监控,这个监控是分析cgroup里的数据,使用的是我们开源的pyadvisor来做的,我们可以通过监控来观察CPU和内存的使用情况,很好的提出优化改进资源使用的建议,另外,对于业务线们,我们推荐他们使用的是Spark里自带的Accumulator,先在Spark Driver上做一个聚合1分钟的指标,然后再往watcher上打他们的业务指标,这样即不会有之前不同host之间的聚合指标的问题,同时也给watcher减轻了压力。
以上就是我们所做的新的Spark架构,综合看来有以下的优点:
-
无需环境配置与部署,走Docker。对于以后也升级也会较方便,可以复用之前Dockerfile。
-
是以直接启动的方式,配置绝对生效,不会出现复杂配置的问题。
-
自动平衡executor。没有Receiver不平衡的问题问题,在某些场景下可以动态增减executor,不会有失败过多而不再拉executor的现象,也不不会有多发或少发executor现象。
-
由于使用Marathon的原因,可以支持多标签,复杂调度,例如业务线有时候需要固定指定的机运行Spark开百名单,同时也为我们以后做迁移有了更多的便利。
由CSDN主办的中国云计算技术大会(CCTC 2017)将于5月18-19日在北京召开,Spark、Container、区块链、大数据四大主题峰会震撼袭来,包括Mesosphere CTO Tobi Knaup,Rancher labs 创始人梁胜、Databricks 工程师 Spark commiter 范文臣等近60位技术大牛齐聚京城,为云计算、大数据以及人工智能领域开发者带来一场技术的盛大Party。现在报名,只需399元就可以聆听近60场的顶级技术专家分享,还等什么,登陆官网(http://cctc.csdn.net/),赶快报名吧!
博客地址:http://blog.yoqi.me/?p=2932

这篇文章还没有评论