从 0 到 1 机器学习的探索与实践 |架构师实践日
2017 年 3 月 4 日,在七牛云架构师实践日「她时代」——大数据与机器学习沙龙中,陈爱珍带来了题为《 从 0 到 1 机器学习的探索与实践 》的分享。主要讲述了机器学习在富媒体领域的应用,并演示了如何使用七牛自定义数据处理平台快速搭建一个机器学习系统,简易的方法让完全不了解机器学习的人也能上手实践,跨入机器学习的门栏。以下是对她演讲内容的整理。

陈爱珍
七牛云布道师,负责七牛多媒体数据处理平台。多年企业级系统的应用运维及分布式系统实战经验,专注于容器、微服务及 DevOps 落地的研究与实践。
我今天的分享主要分为机器学习概念、机器学习平台和人脸识别的实践三个部分。我本身是做图片处理,音视频处理相关工作,不是做机器学习的,但由于工作内容与机器学习有较大关系,因此也有了解机器学习相关的开源项目。今天会简单介绍机器学习的一些概念,然后分享机器学习平台工作的流程。最后,通过 Demo 演示如何实践人脸识别的机器学习项目。希望让大家对机器学习有一个初步的认识。
机器学习概念

人工智能时代

图 1
现在是人工智能时代。而在我们这一代人小时候,可能还没有机会接触计算机。成长过程中,计算机开始普及。长大了以后,出现了机器人。以前对机器人的能力了解不深,自从阿法狗在围棋对战中战胜人类,我们明显发现机器学习在很多行业都已经产生了非常深刻的影响。李开复曾说,现在 90% 的职业在未来会被人工智能所取代,因此,每个人都需要了解机器学习人工智能相关的知识,只有这样才有可能让自己在未来职业路上不被淘汰。
人脑学习 VS 机器学习
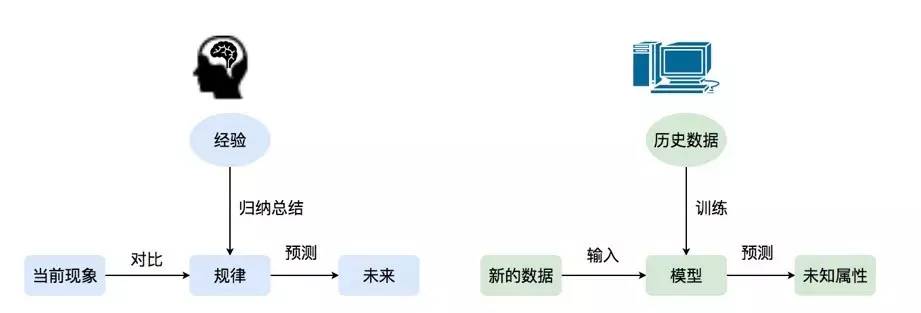
图 2
机器学习跟人脑学习存在区别。人脑学习东西主要根据个人经验,但个人的经验是有限的,数据量非常少。而机器学习基于大数据进行判断,它可以通过大量的历史数据构建模型,再通过模型推测未来。
虽然人脑对一个事物的反应非常快,但在一些复杂的场景中,人脑需要花费较长时间学习总结经验,譬如成为围棋大师需要经过很多年的学习和实践。而机器时代,一个机器人可以通过学习,快速掌握所有的信息。
机器学习可以解决的问题主要分为以下四类:
-
分类问题。即基于数据样本上抽取的特征,判定其属于有限个类别中的哪一个。譬如人脸识别是通过大量人脸图片,学习人脸特征,然后再告诉你这个人是谁。这就是分类问题。
-
回归问题。即根据数据样本上抽取的特征,预测一个连续值的结果。以预测电影票房为例,它是根据线上大家对电影的关注、查询、搜索等情况,并结合相关其他数据,从而推测某一个电影上映后的票房情况。这就是回归的问题。
-
聚类问题。即根据数据样本上抽取的特征,让样本抱团(相近/相关样本在一团内)。譬如,现在我们在使用手机的过程中,经常会被推送一些东西。这是在不知道你的性别,喜好的情况下,根据你的习惯推送给你一些东西。这就是聚类问题。
-
关联问题。譬如当超市里 A 品牌饮料、B 品牌奶粉的销量都很好,我就把这两个产品进行关联,即把它俩放在一起促销,可能会卖的更好,这是关联性数据分析。如果通过人脑做这种分类,或者获取关联性,我们可能要人为看很多数据,学很多数据。但即便如此,人类也不一定能够抓取到这些数据底层潜在的一些关联关系。但通过机器学习就可以解决这些问题。
机器学习的应用

图 3
如图 3 所示,是目前机器学习一些主要的应用。机器学习是通过分析我们原有的一些数据进行判断。比如我们想了解一个植物,却不知道名字。那么,我们可以拍照进行识别。过去,在茫茫人海中找人非常难,但现在利用人脸识别技术,只要对比网上的图片数据库,就能很快的定位。
所以,由于这些机器学习应用的出现,未来我们很多职业都会被取代。以语言识别为例,目前,我们平台上入住了迅飞,过去市场部的同学办一场活动,可能要找速记师进行现场记录,而现在通过将语音录下,再通过迅飞将录音转成文字。很显然,新的技术能给生活带来很大改变。
机器学习平台

机器学习工作流
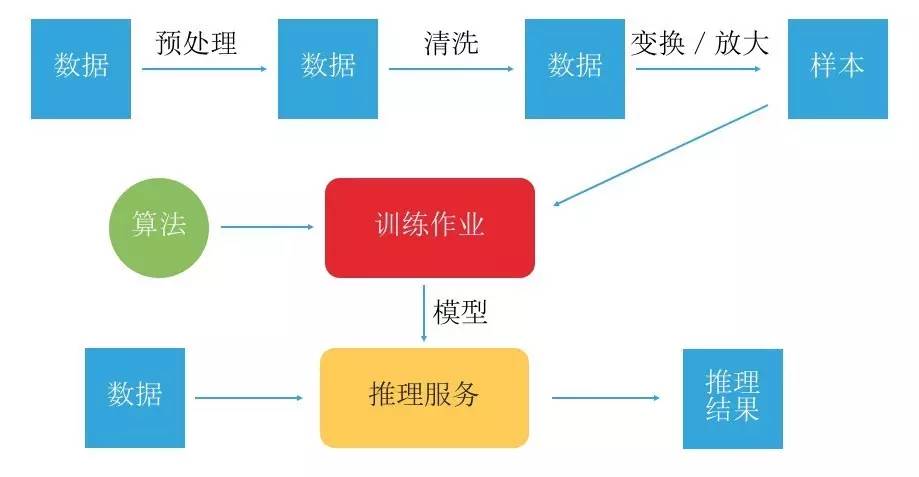
图 4
如图 4 所示为机器学习的工作流。首先,要准备大量有已知特征或者不知道特征的数据。如果对整个数据进行分析,它的体量非常大,因此首先要进行一些预处理,采集关注的数据。接着进行更精确的定位,找到这个数据的特征。然后对这些数据进行训练和学习,从而得到一个模型。此后,当有新的数据进来,便可以通过模型进行判断,这就是机器学习的一个流程。
机器学习平台
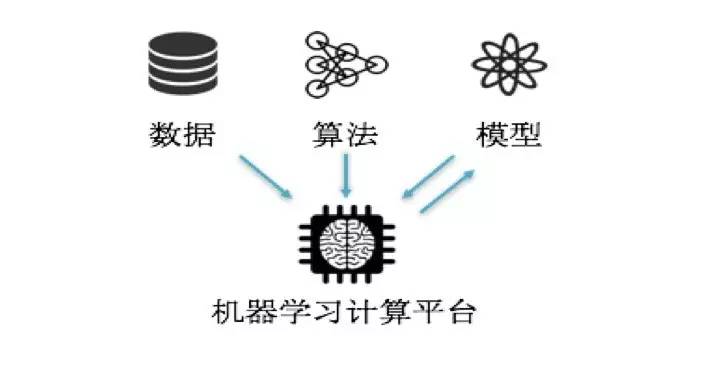
图 5
在机器学习中,算法是非常重要的一个部分。第一,确定自己要用哪个算法来解决问题;第二,要有一个机器学习平台。因为机器学习是对大数据进行分析,因此,它的数据量会非常大,计算量也会非常大。目前,主要用 GPU 做并行计算,这样可以加速计算速度。普通的程序员没有大量的数据,只能取小量数据作为样本来实践自己的功能。如果是商用,则必须以海量的数据作为基底。七牛以云存储起家,因此我们平台上存了大量图片及音视频文件,平台上的用户可以基于这些数据,以及机器学习的平台对图片及音视频文件进行分析,同时我们也引入了大量的供应商为存储用户提供智能数据处理服务。

图 6
机器学习算法
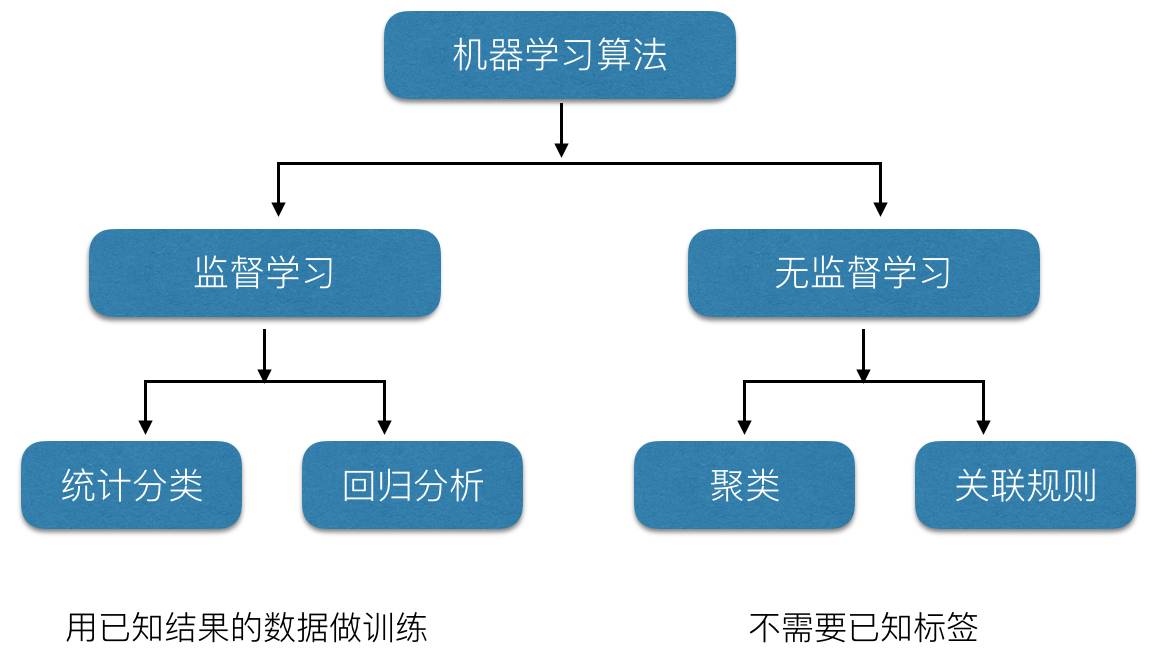
图 7
现在机器学习分为两种:监督学习、无监督学习。监督学习是用已知的结果做训练,即准备一些数据,并进行标记,告诉你这些数据是什么。通过对这些数据的特征进行机器学习,得到一个模型。此后,当你给它一个没有标签的新数据,它就会告诉你这个数据是什么,这就是监督学习,是对有标记的数据进行学习得到一个结果。
无监督学习是事先不知道数据信息。比如互联网上的用户分类、新闻推送等场景,仅仅是因分析的时候,发现数据之间有关联,将它们归为一类。譬如当我们用苹果手机拍照,它会自动把你的照片按照一些特征进行分类。事实上他不知道你照片里的是谁,但他会根据这些照片的特点进行分类,这种人就无监督学习。
机器学习的算法比较多,我列举了如下一些主要的算法:
-
决策树
-
随机森林算法
-
逻辑回归
-
SVM
-
朴素贝叶斯
-
K最近邻算法
-
K均值算法
-
Adaboost 算法
-
神经网络
-
马尔可夫
如果你从事机器学习方面,那么你可能对这些算法有深入的了解。在了解这些算法的时候,我发现都是数据和数学相关内容,如矩阵、离散数学、线性代数等。以前,上大学的时候不明白为什么要学矩阵、离散数学等。但是,当我研究算法的时候,我深深的体会到一句话,学好数理化,走遍天下都不怕。在算法方面,数学学得好用处真的很大。我本身不是做机器学习的,因此只是大概了解这些算法在什么场景下可能会用到。我今天讲的主要是神经网络,即深度学习。其他的算法我不细讲,大家有兴趣可以自己去了解一下。
深度学习主流框架

图 8
如图 8 所示,我总结了一些主流的框架,大家可能对 TensorFlow 比较熟,后面举例的时候,会讲和 TensorFlow 相关的内容。七牛的 AVA 弹性深度学习平台使用的框架有 Caffe、MXNet、Tensorflow。由于七牛有存储业务,因此有大量富媒体存储的用户,我们的用户可能需要对富媒体做一些机器学习的东西,所以我们也为用户提供机器学习的平台。我们现在主要是用 Caffe 多一些,因为 Caffe 稳定一些,适合生产用。
因为我自己本身做容器技术的,我觉得现在这个时代最好的一点就是有 Docker 容器。即当你要去学一些新技术时会比较快,比如不需要自己安装,可以直接下载别人做好的镜像。特别是有些安装复杂的软件,整个安装过程可能需要很久,但是有了 Docker 之后,就可以省去安装的过程,可以更快速的了解和使用。对于这些框架,有些已经有容器镜像了,大家想了解可以直接下载镜像进行学习。
人脸识别的实践

人的视觉系统
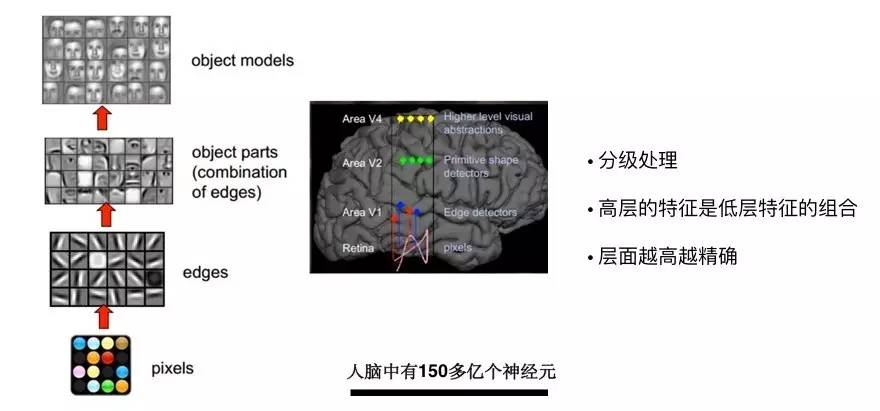
图 9
接下来,我分享一个人脸识别的实践。人脸识别是基于神经网络,即大家目前非常关注的深度学习算法。人脸识别系统可以在很短的时间内对图片进行识别。事实上,人类用大脑进行识别也有一个过程。如图 9 所示为人的视觉系统,它会分层的逐步强化人物特征,根据这些特征一步一步告诉你这个人是谁。计算速度快到让你没有感觉到这个过程,是因为我们人脑中有 150 多亿个神经元。当我们进行识别分析,或者推理的时候,拿到的特征越多,更容易知道这个特征代表的是什么。
神经网络
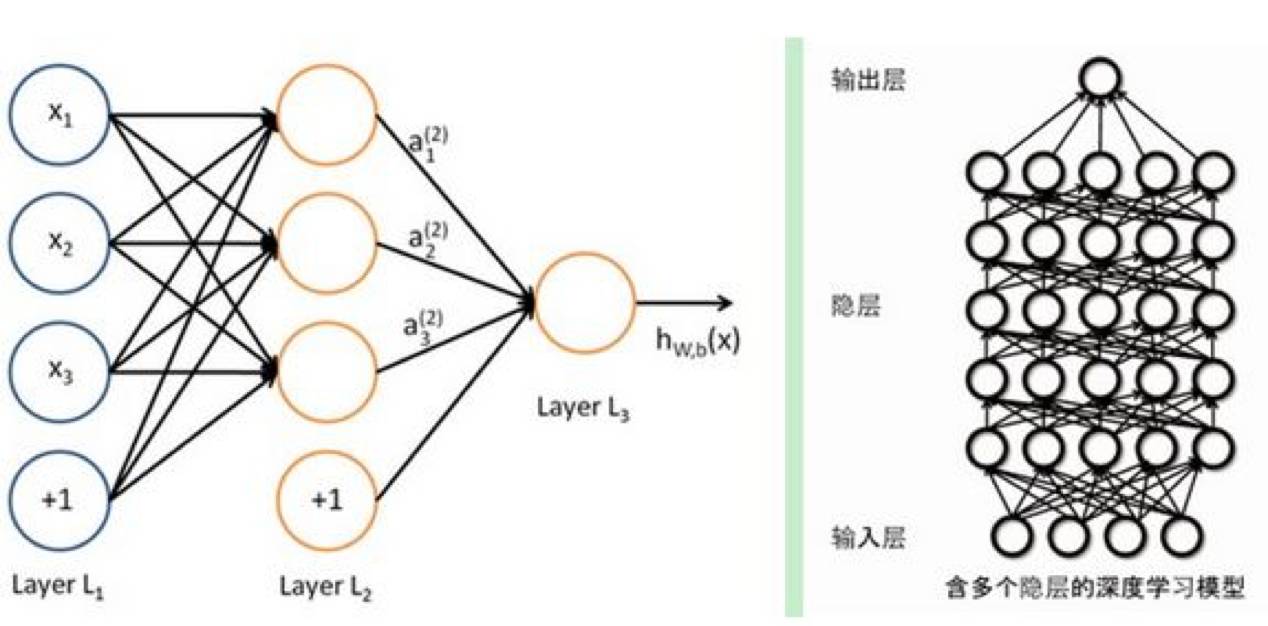
图 10
神经网络是一种模拟大脑的算法,是一类模式匹配算法。通常用于解决分类和回归问题。是由具有适应性的简单单元组成的广泛并行互连的网络,它的组织能够模拟生物神经系统对真实世界物体所作出的交互反应。
神经网络是机器学习的一个庞大的分支,有几百种不同的算法。深度学习就是其中的一类算法,深度学习其实也是仿造人类神经网络的方式进行识别。神经网络本身只有三层,即根据一些特征,自己的大脑会进行一些处理,从而得到一个结果。深度学习与神经网络的区别在于神经网络会有很多层。
下面通过对 Google Tensorflow 游乐场、开源项目 Openface 人脸识别实践和在线预测系统等三个平台进行了 Demo 来演示人脸识别的实践,
Demo 演示
一、Google Tensorflow 游乐场
Tensorflow 是 Google 推出的机器学习开源平台。而使用 Google Tensorflow 游乐场可以在浏览器中训练自己的神经网络,通过图像更直观地了解神经网络的工作原理。
网址:http://playground.tensorflow.org/
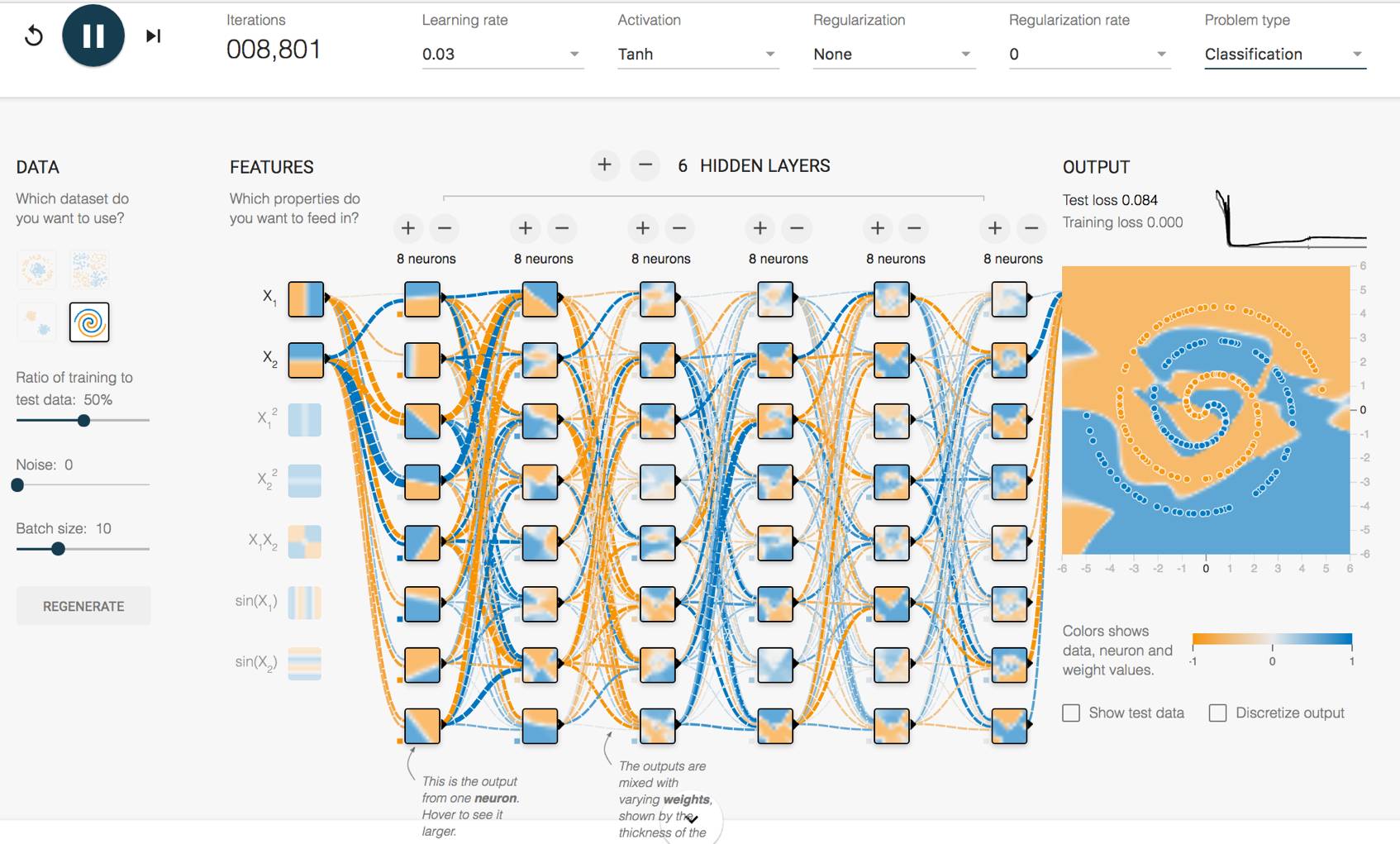
图 11
二、开源项目 Openface 人脸识别实践
Openface 是用 Torch 和 Python 实现的一个基于深度神经网络的开源人脸识别系统。
网址:https://cmusatyalab.github.io/openface/
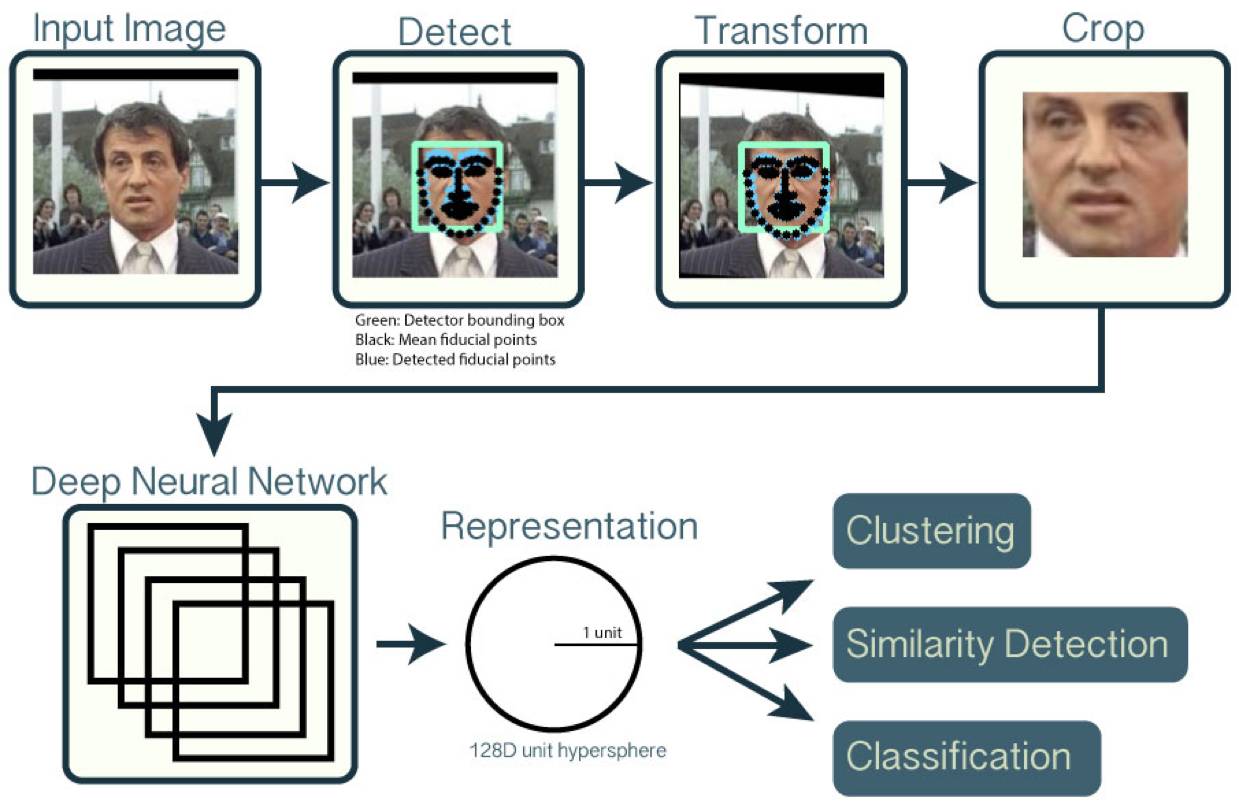
图 12
可以直接通过 Docker 下载这个开源项目的镜像,启动容器后通过以下四步完成人脸识别:

三、构建在线预测系统
七牛的自定义数据处理平台提供高性能 GPU 计算机群及自动伸缩容器集群,方便开发者对云存储中的大量图片/音视频/文档数据进行云端机器学习,包括图像分类、视频分析、语音识别以及自然语言处理等等。简单易用的自定义数据处理平台可以帮助开发者快速构建机器学习应用,实现在云端进行训练、分类和预测。
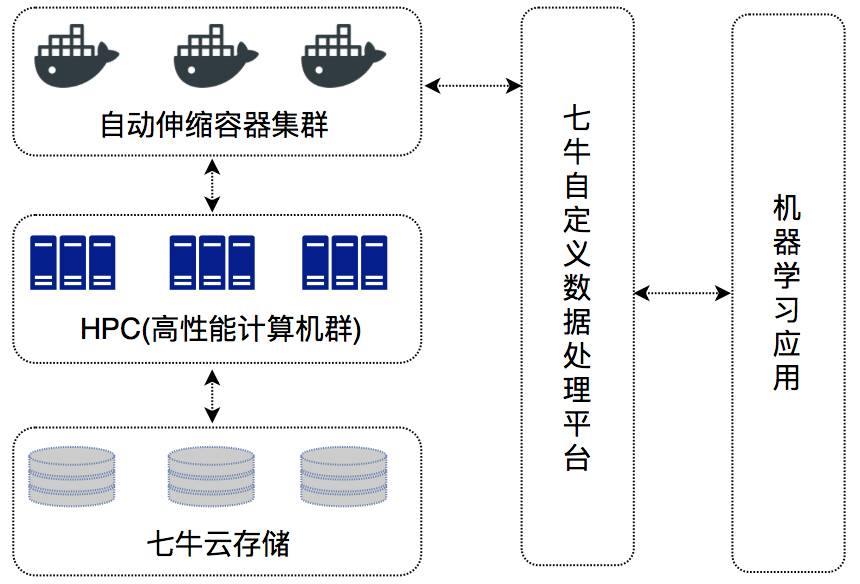
图 13
下面通过 Demo 演示如何基于七牛自定义数据处理平台搭建一个简单的的机器学习在线预测系统,帮助提供基本的在线预测服务。
网址:https://portal.qiniu.com/signin
机器学习应用构建成容器镜像后可一键式部署在七牛自定义数据处理平台,就可以很方便的构建一个在线预测系统。如人脸识别项目,可以在七牛自定义数据处理平台注册一个名为 faced 的自定义数据处理,在使用时只需在图片 URL 后面加上分隔符 ?及 faced ,即可立即识别出这张图片是谁的照片。
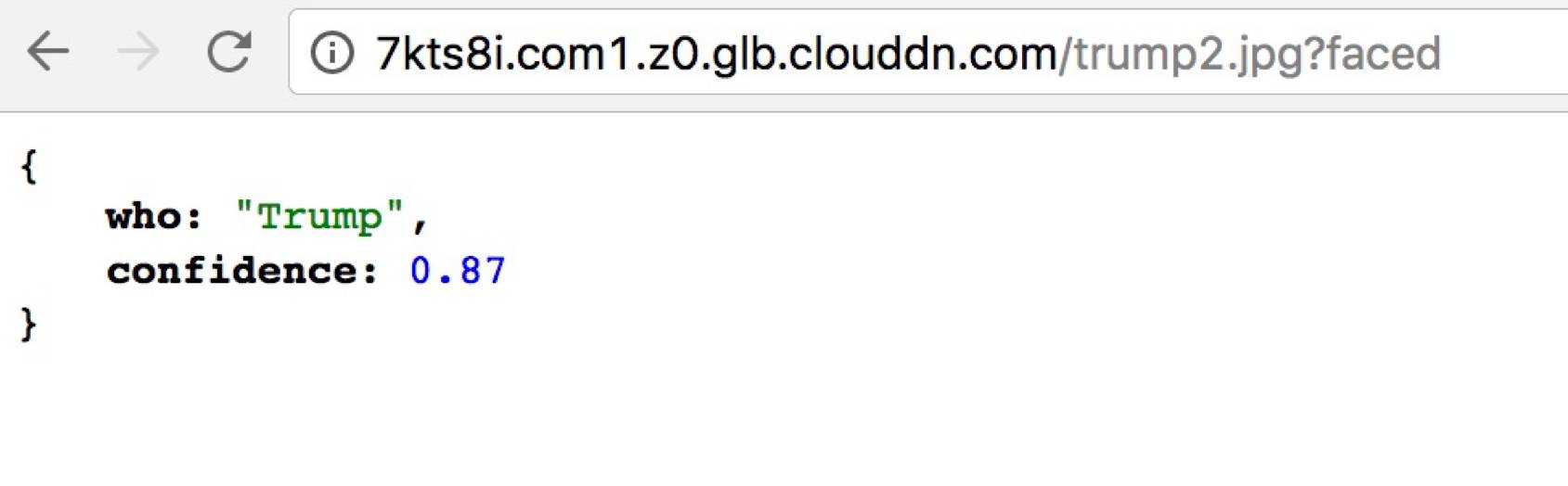
图 14

具体「如何快速部署一个机器学习在线预测系统」如何快速部署一个机器学习在线预测系统,请点击「阅读原文」查看。

这篇文章还没有评论