Batch Normalization原理及实现
本系列文章面向深度学习研发者,希望通过 Image Caption Generation,一个有意思的具体任务,深入浅出地介绍深度学习的知识。本系列文章涉及到很多深度学习流行的模型,如CNN,RNN/LSTM,Attention等。本文为第10篇。
作者:李理
目前就职于环信,即时通讯云平台和全媒体智能客服平台,在环信从事智能客服和智能机器人相关工作,致力于用深度学习来提高智能机器人的性能。
1. 内容简介
前面的部分介绍了卷积神经网络的原理以及怎么使用Theano的自动梯度来实现卷积神经网络,这篇文章将继续介绍卷积神经网络相关内容。
首先会介绍DropOut和Batch Normalization技术,dropout可以提高模型的泛化能力。而Batch Normalization是加速训练收敛速度的非常简单但又好用的一种实用技术,我们会通过cs231n的作业2来实现DropOut和Batch Normalization。
然后我们再完成作业2的另外一部分——通过计算图分解实现卷积神经网络。
接下来是简单的介绍使用caffe来训练imagenet的技术已经怎么在python里使用caffe,这些技术在后面会用到。
我们最后会简单的介绍一下图像分类的一些最新技术,包括极深度的ResNet(152层的ResNet),Inception。
2. Batch Normalization
2.1 简介
前面我们也讨论过来了,训练神经网络我们一般使用mini-batch的sgd算法,使用mini-batch而不是一个样本的好处是作为全部样本的采样,一个mini-batch的“随机”梯度和batch的梯度方向更接近(当然这是相对于一个训练样本来说的);另外一个好处是使用一个mini-batch的数据可以利用硬件的数据并行能力。比如通常的batch是几十到几百,而且为了利用数据并行的lib如blas或者GPU,一般都是8的倍数,比如16或者128这样的数字。
根据之前我们训练全连接网络的经验(如果读者网络可以再回归一下我们之前的文章,训练一个5层的全连接网络来识别cifar10的图片,要调到50%以上的准确率的例子,参考《自动梯度求解——使用自动求导实现多层神经网络》http://geek.csdn.net/news/detail/125097),要想让训练能收敛,选择合适的超参数如learning_rate或者参数的初始化非常重要,如果选择的值不合适,很可能无法收敛。当然使用更好的算法如momentum或者adam等可以让算法更容易收敛,但是对于很深的网络依然很难训练。
因为层次越多,error往前传播就越小,而且很多神经元会“saturation”。比如sigmoid激活函数在|x|比较小的时候图像解决直线y=x,从而梯度是1,但随着|x|变大,梯度变得很小,从而参数的delta就非常小,参数变化很小。使用ReLU这样的激活函数能缓解saturation的问题,但是还有“internal covariate shift”的问题(接下来会介绍这个问题)依然很难解决。而Batch Normalization就能解决这个问题同时也能解决saturation的问题。
Batch Normalization是Google的Sergey Ioffe 和 Christian Szegedy提出的,相同的网络结构,使用这种方法比原始的网络训练速度要提高14倍。作者通过训练多个模型的ensemble,在ImageNet上的top5分类错误率降到了4.8%。
2.2 covariate shift 和 internal covariate shift
2.2.1 covariate shift
假设一个模型的输入是X(比如在MNIST任务,X是一个784的向量),输出是Y(比如MNIST是0-9的10个类别)。很多Discriminative 模型学到的是P(Y|X),神经网络也是这样的模型。而covariate shift问题是由于训练数据的领域模型 Ps(X) 和测试数据的 Pt(X) 分布不一致造成的,这里的下标s和t是source和target的缩写,代表训练和测试。
乍一看这个应该不是什么问题。毕竟我们的目标是分类,只要 Ps(Y|X) 和 Pt(Y|X) 是一样的就行了。和X的分别 Ps(X) 以及 Pt(X) 有什么关系呢?
问题的关键是我们训练的模型一般都是参数化的模型 Ps(Y|X;θ) ,也就是我们用一个参数化的模型来学习X和Y的关系。我们根据训练数据上的loss来选择最佳的 θ∗。但是在很多时候,我们没法学习出一个完美的模型,因此总会有一些X使得 P(Y|X)≠P(Y|X;θ) 。那在这个时候P(X)就会带来影响。
比如说我这个模型在 X1和 X2 都会出错,也就是都有loss。我们可以调整参数,当然完美的情况是调参的结果使得两个点上的loss都变小。可惜这一点做不到,我们只能是一个变小一个变大,那么我们应该倾向与哪个呢?很显然要看 P(X1)和 P(X2) 哪个大。如果 P(X1) 大,也就是说 X1 更容易出现,那么当然应该让 X1 的loss更小(从而分类正确的可能性更大,如果是回归的话更是这样)。
现在问题来了,如果训练数据中Ps(X)和测试数据Pt(X)不一样,那么就会带来问题。举一个极端的例子,假设我们的X只有两种取值数据1和数据2,他们的类别是不同的,但是我们的feature很不好,根本没法区分出X1和X2来,也就是说X1=X2。因此我们的模型肯定无法正确的分类出数据1和数据2来。但是我们的模型必须做出选择,那怎么选择呢?当然要看P(X1)和P(X2)哪个大,我们尽量把出现概率大的那个分对。如训练的时候数据1出现的概率大,那么我们的分类器会把他分类成数据1的类别。但是如果我们测试的数据确实数据2的概率大,那么我们的模型就会有问题。
解决这个问题的方法有很多,其中一种思路是重新训练一个新的模型,对训练数据进行”加权“。不过这和我们的Batch Normalization关系不大,就不展开了。介绍它的目的是让大家知道有这样一个问题,如果在实际的工作中碰到训练数据的分布和测试数据的分布不一样,要想想这个会不会带来问题。
2.2.2 internal covariate shift
通过前面的分析,我们知道如果训练时和测试时输入的分布变化,会给模型带来问题。当然在日常的应用中,这个问题一般不会太明显,因为一般情况数据的分布差别不会太大(尤其是P(Y|X)不会,否则之前的训练数据完全没法用了,可以认为是两个不同的任务了),但是在很深的网络里这个问题会带来问题,使得训练收敛速度变慢。因为前面的层的结果会传递到后面的层,而且层次越多,前面的细微变化就会带来后面的巨大变化。如果某一层的输入分布总是变化的话,那么它就会无所适从,很难调整好参数。我们一般会对输入数据进行”白化“除理,使得它的均值是0,方差是1。但是之后的层就很难保证了,因为随着前面层参数的调整,后面的层的输入是很难保证的。比较坏的情况是,比如最后一层,经过一个minibatch,把参数调整好的比之前好一些了,但是它之前的所有层的参数也都变了,从而导致下一轮训练的时候输入的范围都发生变化了,那么它肯定就很难正确的分类了。这就是所谓的internal covariate shift。
2.3 解决方法——Batch Normalization
那怎么能解决这个问题呢?如果我们能保证每次minibatch时每个层的输入数据都是均值0方差1,那么就可以解决这个问题。因此我们可以加一个batch normalization层对这个minibatch的数据进行处理。但是这样也带来一个问题,把某个层的输出限制在均值为0方差为1的分布会使得网络的表达能力变弱。因此作者又给batch normalization层进行一些限制的放松,给它增加两个可学习的参数 β 和 γ ,对数据进行缩放和平移,平移参数 β 和缩放参数 γ 是学习出来的。极端的情况这两个参数等于mini-batch的均值和方差,那么经过batch normalization之后的数据和输入完全一样,当然一般的情况是不同的。
Batch Normalization的算法很简单,如下图所示:

2.4 Batch Normalization的预测
我们训练时使用一个minibatch的数据,因此可以计算均值和方差,但是预测时一次只有一个数据,所以均值方差都是0,那么BN层什么也不干,原封不动的输出。这肯定会用问题,因为模型训练时都是进过处理的,但是测试时又没有,那么结果肯定不对。
解决的方法是使用训练的所有数据,也就是所谓的population上的统计。原文中使用的就是这种方法,不过这需要训练完成之后在多出一个步骤。另外一种常见的办法就是基于momentum的指数衰减,这种方法就是我们下面作业要完成的算法。
公式如下:
running_mean = momentum * running_mean + (1 - momentum) * sample_mean
running_var = momentum * running_var + (1 - momentum) * sample_var
如果读者做过滤波,这和低通滤波器类似。每次更新时把之前的值衰减一点点(乘以一个momentum,一般很大,如0.9,0.99),然后把当前的值加一点点进去(1-momentum)。
当然极端的情况下这种方法计算出来的值和实际的平均值是有差异的,比如如下例子
100, 100, 100 , … 1, 1, 1
比如有两百个数据,100个100和100个1,那么平均值应该是55.5。如果采样不好的话,前面全是100,后面全是1,那么用这种算法计算的就接近1。反之如果前面全部是1,后面全是100,那么结果就接近100。当然一般情况我们的采样是均匀的,那么计算出来就是解决55.5。
3. Batch Normalization的实现
3.1 作业
安装参考 http://cs231n.github.io/assignments2016/assignment2/。之前的文章也有介绍,请参考。包括数据的下载(cifar10有100多M)和cpython扩展的安装。安装好之后运行 ipython notebook打开BatchNormalization.ipybn
3.2 cell1和cell2
第一个直接运行就可以了。如果运行有问题,可能是需要的lib没有安装好,如果提示cython的问题,记得python setup.py build_ext –inplace。如果运行cell2找不到cifar10数据,可能是路径问题,简单的办法是修改data_utils.py,改成绝对路径就行了,请参考我下面的例子。
def get_CIFAR10_data(num_training=49000, num_validation=1000, num_test=1000): """ Load the CIFAR-10 dataset from disk and perform preprocessing to prepare it for classifiers. These are the same steps as we used for the SVM, but condensed to a single function. """ # Load the raw CIFAR-10 data cifar10_dir = '/home/mc/cs231n/assignment2/cs231n/datasets/cifar-10-batches-py'
3.3 cell3
def batchnorm_forward(x, gamma, beta, bn_param): """ 输入: - x: 输入数据 shape (N, D) - gamma: 缩放参数 shape (D,) - beta: 平移参数 shape (D,) - bn_param: 包含如下参数的dict: - mode: 'train' or 'test'; 用来区分训练还是测试 - eps: 除以方差时为了防止方差太小而导致数值计算不稳定 - momentum: 前面讨论的momentum. - running_mean: 数组 shape (D,) 记录最新的均值 - running_var 数组 shape (D,) 记录最新的方差 返回一个tuple: - out: shape (N, D) - cache: 缓存反向计算时需要的变量 """ mode = bn_param['mode'] eps = bn_param.get('eps', 1e-5) momentum = bn_param.get('momentum', 0.9) N, D = x.shape running_mean = bn_param.get('running_mean', np.zeros(D, dtype=x.dtype)) running_var = bn_param.get('running_var', np.zeros(D, dtype=x.dtype)) out, cache = None, None if mode == 'train': ############################################################################# # TODO: Implement the training-time forward pass for batch normalization. # # Use minibatch statistics to compute the mean and variance, use these # # statistics to normalize the incoming data, and scale and shift the # # normalized data using gamma and beta. # # # # You should store the output in the variable out. Any intermediates that # # you need for the backward pass should be stored in the cache variable. # # # # You should also use your computed sample mean and variance together with # # the momentum variable to update the running mean and running variance, # # storing your result in the running_mean and running_var variables. # ############################################################################# x_mean=x.mean(axis=0) x_var=x.var(axis=0) x_normalized=(x-x_mean)/np.sqrt(x_var+eps) out = gamma * x_normalized + beta running_mean = momentum * running_mean + (1 - momentum) * x_mean running_var = momentum * running_var + (1 - momentum) * x_var cache = (x, x_mean, x_var, x_normalized, beta, gamma, eps) ############################################################################# # END OF YOUR CODE # ############################################################################# elif mode == 'test': ############################################################################# # TODO: Implement the test-time forward pass for batch normalization. Use # # the running mean and variance to normalize the incoming data, then scale # # and shift the normalized data using gamma and beta. Store the result in # # the out variable. # ############################################################################# x_normalized = (x - running_mean)/np.sqrt(running_var +eps) out = gamma*x_normalized + beta ############################################################################# # END OF YOUR CODE # ############################################################################# else: raise ValueError('Invalid forward batchnorm mode "%s"' % mode) # Store the updated running means back into bn_param bn_param['running_mean'] = running_mean bn_param['running_var'] = running_var return out, cache
代码其实比较简单,首先是使用numpy.mean和var计算这个minibatch的均值和方差,然后计算x_normalized,然后用gamma和beta对x_normalized进行缩放和平移。为了防止sqrt(running_var)下溢到0导致除以零,我们除以np.sqrt(running_var_+ eps)
上面是训练的代码,测试时我们直接使用running_mean和running_var而不需要通过minibatch计算。
最后,我们吧当前的running_mean和running_var更新到bn_param里,以便下次minibatch训练时使用。
下图是运行的结果:
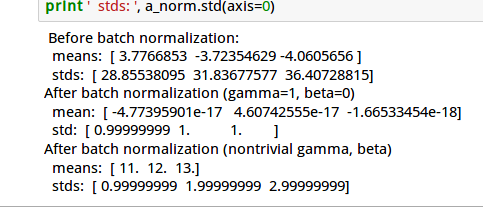
如果After batch normalization(gamma=1, beta=0),我们得到的mean接近0【比如图中10的负18次方】,std接近1。那么说明我们的代码没有问题。
3.4 cell4
我们上面已经实现了test时的代码,直接运行,得到类似下图的结果:
这次的结果means接近0,方差接近1。不过因为使用的是全局的均值和方差,所以随机性要比之前大。
3.5 cell5
接下来我们实现反向梯度的计算,打开layers.py实现batchnorm_backward函数。
如果对计算图还不了解的读者可以参考《自动梯度求解——cs231n的notes》 http://geek.csdn.net/news/detail/112326 和《自动梯度求解——使用自动求导实现多层神经网络》http://geek.csdn.net/news/detail/125097
(x, x_mean, x_var, x_normalized, beta, gamma, eps) = cache N = x.shape[0] dbeta = np.sum(dout, axis=0) dgamma = np.sum(x_normalized*dout, axis = 0) dx_normalized = gamma* dout dx_var = np.sum(-1.0/2*dx_normalized*(x-x_mean)/(x_var+eps)**(3.0/2), axis =0) dx_mean = np.sum(-1/np.sqrt(x_var+eps)* dx_normalized, axis = 0) + 1.0/N*dx_var *np.sum(-2*(x-x_mean), axis = 0) dx = 1/np.sqrt(x_var+eps)*dx_normalized + dx_var*2.0/N*(x-x_mean) + 1.0/N*dx_mean
前面的函数参数说明和返回值就不贴了,上面是我们需要补充的代码
3.5.1.第1行
首先是从cache里恢复所有的中间变量,顺序和前面的forward一致。
3.5.2. 第2行
从x.shape里取得batchSize N,后面会用到。
3.5.3. 第3-5行
计算dbeta和dgamma,我们根据下面的式子
out = gamma * x_normalized + beta
可以得到:
dbeta = np.sum(dout, axis=0) dgamma = np.sum(x_normalized*dout, axis = 0) dx_normalized = gamma* dout
注意,前面的gamma*x_mormalized使用了broadcasting,gamma是一个数,而x_normalized是一个向量,所以求梯度时需要求和,加上beta也是同样的道理。
3.5.4. 第6行
根据式子:
x_normalized=(x-x_mean)/np.sqrt(x_var+eps)
我们简单的推导一下:
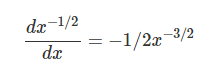
因此可以得到dx_var:
dx_var = np.sum(-1.0/2*dx_normalized*(x-x_mean)/(x_var+eps)**(3.0/2), axis =0)
np.sum的原因和上面是一样的。
3.5.5. 第7行
和上面类似,读者可能很快能推导出下面的代码:
dx_mean = np.sum(-1/np.sqrt(x_var+eps)* dx_normalized, axis = 0)
不过如果细心的读者和前面的代码对比,发现会少了一部分,为什么呢?
从
x_normalized=(x-x_mean)/np.sqrt(x_var+eps)
看,x_mean似乎只影响x_normalized,但是请注意这行代码:
x_var=x.var(axis=0)
回忆一下方差的定义
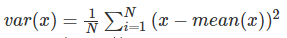
我可以看到x_mean还是会影响x_var的。
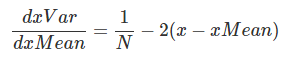
所以得到另外一部分:
1.0/N*dx_var *np.sum(-2*(x-x_mean), axis = 0)
3.5.6 第8行
x影响的变量是:
x_mean=x.mean(axis=0) x_var=x.var(axis=0) x_normalized=(x-x_mean)/np.sqrt(x_var+eps)
所以dx也分为3部分:
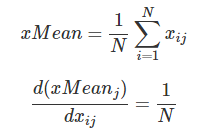
所以dx的一部分等于 1/N*dx_mean
同样的对于方差部分,我们可以得到dx_var 2.0/N (x-x_mean)
最后是
x_normalized=(x-x_mean)/np.sqrt(x_var+eps)
我们可以计算得到1/np.sqrt(x_var+eps)*dx_normalized
三部分加起来就是dx
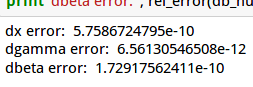
完成代码后我们执行cell5得到如下的结果:
3.6 cell6
我们实现一个更优化的方案。【注,我们前面的实现已经还比较优化了,这个作业的初衷是让我们用更”原始“的计算图分解,比如把np.mean分解成加法和除法,有兴趣的读者可以参考 Understanding the backward pass through Batch Normalization Layer https://kratzert.github.io/2016/02/12/understanding-the-gradient-flow-through-the-batch-normalization-layer.html ,然后再优化成我们的版本】
不过我们的代码还有一个地方可以优化的,我们看看dvar的第二项: 1.0/N dx_var np.sum(-2 (x-x_mean), axis = 0)
这一项等于0。为什么?我们举个实际的例子好了。
为了简化,我们假设x是1,D的(batchSize=1)。
x=[1,2,3] x_mean=1/3(1+2+3)=2
那么 (1-x_mean) + (2-x_mean) + (3-x_mean)=(1+2+3)- xMean*3=0
也就是对x减去x的均值然后求和等于0
所以我们可以把这一项去掉。
运行cell6,这点代码会比较两个算法的diff,应该是0。

我们的代码dbeta和dgamma是完全一样的,但是dvar不同,从而导致dx有细微的差异【计算的舍入误差】
3.7 cell7
修改fc_net.py的FullyConnectedNet类让它支持batch normalization
3.7.1增加affine_bn_relu层
在fc_net.py里定义affine_bn_relu_forward和affine_bn_relu_backward函数
def affine_bn_relu_forward(x, w, b, gamma, beta, bn_param): affine_out, fc_cache = affine_forward(x, w, b) bn_out, bn_cache = batchnorm_forward(affine_out, gamma, beta, bn_param) relu_out, relu_cache = relu_forward(bn_out) cache = (fc_cache, bn_cache, relu_cache) return relu_out, cachedef affine_bn_relu_backward(dout, cache): fc_cache, bn_cache, relu_cache = cache drelu_out = relu_backward(dout, relu_cache) dbn_out, dgamma, dbeta = batchnorm_backward(drelu_out, bn_cache) dx, dw, db = affine_backward(dbn_out, fc_cache) return dx, dw, db, dgamma, dbeta
代码和之前的affine_relu_forward/backward类似,这里不再赘述。
3.7.2 修改_init_
在这个函数里增加batch_normalization相关参数的初始化,注意最后一层是不需要batch normalization的。
for i in range(1, self.num_layers + 1): if use_batchnorm and i != self.num_layers: self.params['beta' + str(i)] = np.zeros(layer_output_dim) self.params['gamma' + str(i)] = np.ones(layer_output_dim)
3.7.3 修改loss函数
首先在最上面增加 affine_bn_relu_cache = {}
然后是训练的forward部分代码的修改【注意和以前代码的比较,以前的代码没有else部分】
for i in range(1, self.num_layers): keyW = 'W' + str(i) keyb = 'b' + str(i) if not self.use_batchnorm: current_input, affine_relu_cache[i] = affine_relu_forward(current_input, self.params[keyW], self.params[keyb]) else: key_gamma = 'gamma' + str(i) key_beta = 'beta' + str(i) current_input, affine_bn_relu_cache[i] = affine_bn_relu_forward(current_input, self.params[keyW], self.params[keyb], self.params[key_gamma], self.params[key_beta], self.bn_params[i - 1])
最后是训练的backward部分的代码修改
for i in range(self.num_layers - 1, 0, -1): if not self.use_batchnorm: affine_dx, affine_dw, affine_db = affine_relu_backward(affine_dx, affine_relu_cache[i]) else: affine_dx, affine_dw, affine_db, dgamma, dbeta = affine_bn_relu_backward(affine_dx, affine_bn_relu_cache[i]) grads['beta' + str(i)] = dbeta grads['gamma' + str(i)] = dgamma
然后我们运行这个cell,梯度的误差应该很小。
3.8 cell8-9
接下来我们训练一个6层的全连接网络,分别测试用batch norm和不用的效果
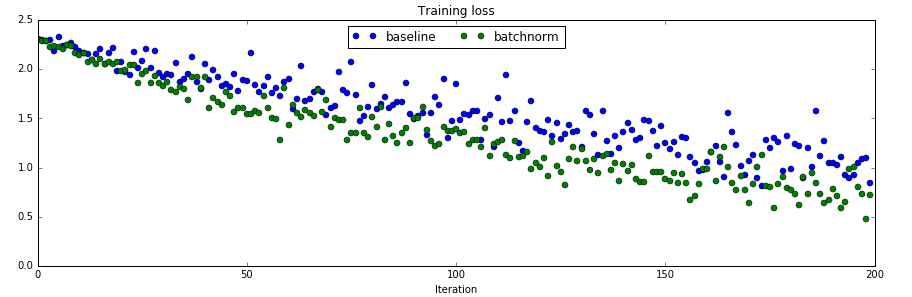
训练loss的对比
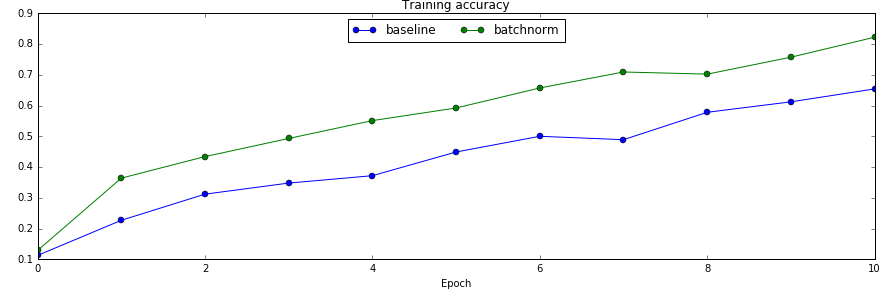
训练集上的准确率对比
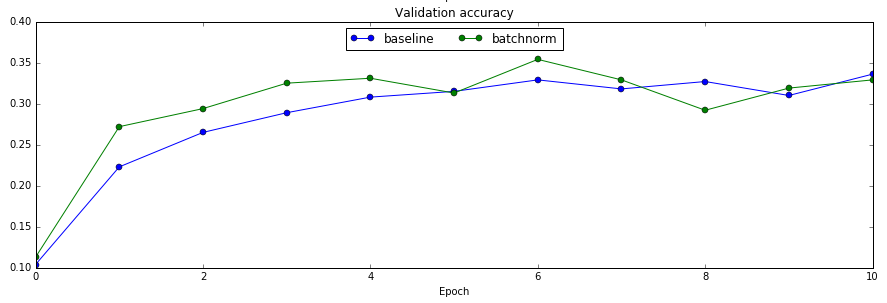
验证集上的对比
从对比实验可以看出,使用了batch normalization收敛速度确实变快了。
3.9 cell10-11
我们最后对比一下是否使用batch norm是否能让训练与参数初始化不那么敏感。因为我们之前的经验,参数的初始化会极大影响到最后训练的结果,这让模型训练变得很tricky,我们需要不断的尝试才能找到比较好的初始化参数。我们前面说过,batch norm可以让这个问题得到缓解,那么我们来验证一下。
运行这两个cell的效果如下图:
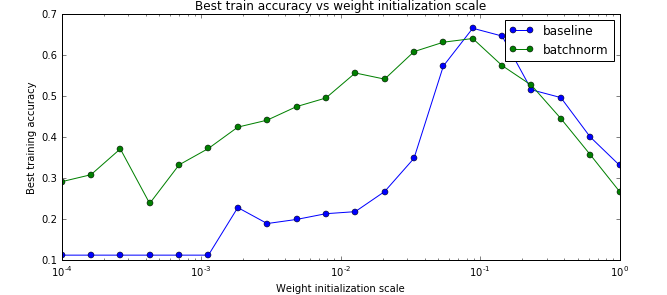
训练数据的最高准确率
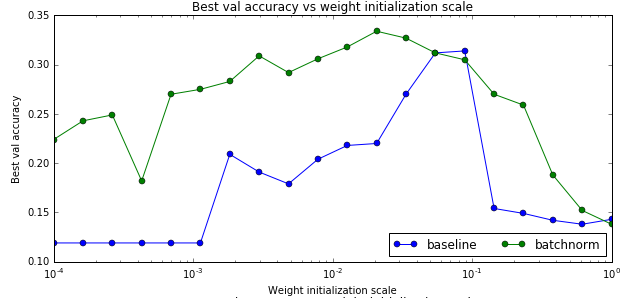
测试数据的最高准确率
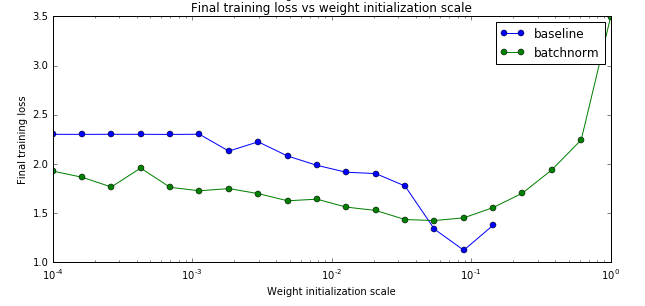
最终的最高准确率
从上面的图可以看出,确实使用了bn后参赛初始化的问题变得好一些了【当然不会完全解决】。另外最后一个图不使用batch norm的baseline对于初始化过大的参数会出现不能训练的情况,因此图中有部分不能绘制。
在接下来的文章中,将会讲到卷积神经网络的实现部分以及使用caffe来训练imagenet的技术,还将介绍到图像分类的一些最新技术,欢迎持续关注。
相关文章:
李理:从Image Caption Generation理解深度学习(part I)
http://geek.csdn.net/news/detail/97193
李理:从Image Caption Generation理解深度学习(part II)
http://geek.csdn.net/news/detail/98776
李理:从Image Caption Generation理解深度学习(part III)
http://geek.csdn.net/news/detail/104187
李理:自动梯度求解 反向传播算法的另外一种视角
http://geek.csdn.net/news/detail/111948
李理:自动梯度求解——cs231n的notes
http://geek.csdn.net/news/detail/112326
李理:自动梯度求解——使用自动求导实现多层神经网络
http://geek.csdn.net/news/detail/125097
李理:详解卷积神经网络
http://geek.csdn.net/news/detail/127365
李理:Theano tutorial和卷积神经网络的Theano实现 Part1
http://geek.csdn.net/news/detail/131362
李理:Theano tutorial和卷积神经网络的Theano实现 Part2
http://geek.csdn.net/news/detail/131516
博客地址:http://blog.yoqi.me/?p=2830
这篇文章还没有评论