用Spark分析Amazon的8000万商品评价(内含数据集、代码、论文)
点击上方“云栖社区”可以订阅哦
摘要
尽管数据科学家经常通过分布式云计算来处理数据,但是即使在一般的笔记本电脑上,只要给出足够的内存,Spark也可以工作正常(在这篇文章中,我使用2016年MacBook Pro / 16GB内存,分配给Spark 8GB内存)。
亚马逊的商品评论和评分是一个非常重要的业务。 亚马逊上的客户经常基于这些评论做出购买决定,并且单个不良评论可以导致潜在购买者重新考虑。 几年前,我写了一篇非常受欢迎的博客文章,题为“120万亚马逊评论统计分析“。
阅读地址:http://minimaxir.com/2014/06/reviewing-reviews/?spm=5176.100239.blogcont69165.8.Eo3vpV
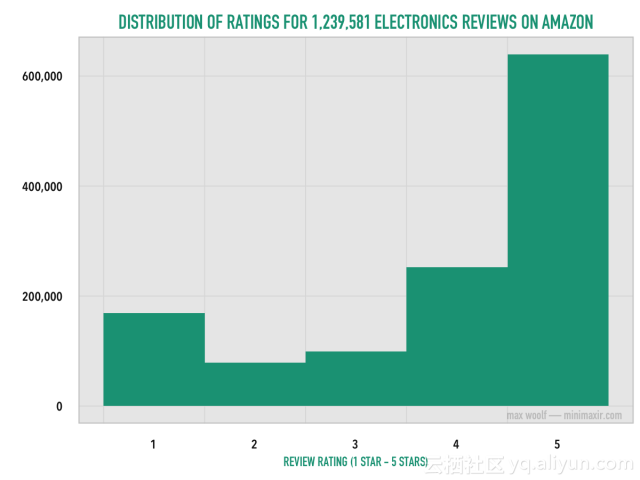
当时,我只限于1200万评论,因为尝试处理更多的数据会导致内存不足,以至于我的R语言代码需要运行几个小时。
Apache Spark是一个高效的开源大数据计算框架,在过去几年中已经非常流行(对于使用Spark和Python的好教程,我推荐免费的eDX课程)。尽管数据科学家经常通过分布式云计算来处理数据,但是即使在一般的笔记本电脑上,只要给出足够的内存,Spark也可以工作正常(在这篇文章中,我使用2016年MacBook Pro / 16GB内存,分配给Spark 8GB内存)。
我写了一个简单的Python脚本,用来合并Julian McAuley、Rahul Pandey和Jure Leskovecucehua在2015年发布“Inferring Networks of Substitutable and Complementary Products”(http://cseweb.ucsd.edu/~jmcauley/pdfs/kdd15.pdf?spm=5176.100239.blogcont69165.10.Eo3vpV&file=kdd15.pdf)论文时准备的亚马逊产品评论数据集(http://jmcauley.ucsd.edu/data/amazon/?spm=5176.100239.blogcont69165.11.Eo3vpV)中每个类别的评级数据 。成果是一个4.53 GB的CSV,肯定不能在Microsoft Excel中打开。选取和整合的数据集包括:留下评论的用户的用户名,指明是哪一个接收评论亚马逊产品的id,从1到5的用户给出的评级,以及评论写入的时间(精确到天)。 我们还可以从数据子集的名称推断已评价产品的类别。
然后,使用面对R语言的新的升级包,我可以使用一个spark_connect()命令轻松启动本地Spark集群,并使用单个spark_read_csv()命令很快将整个CSV加载到集群中。
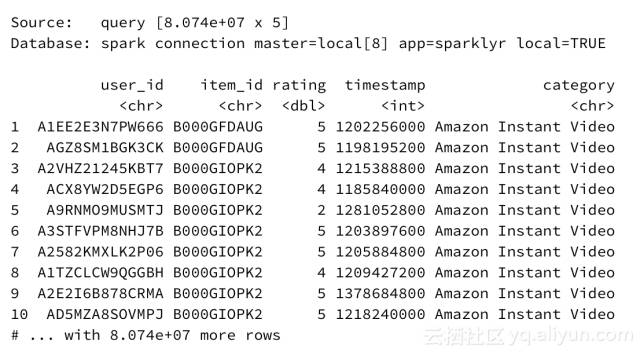
在数据集中总共有8074万条记录,即8.074e + 07条。如果使用传统工具(如dplyr或甚至Python pandas)高级查询,这样的数据集将需要相当长的时间来执行。
使用sparklyr,操作实际很大的数据就像对只有少数记录的数据集执行分析一样简单(并且比上面提到的eDX类中教授的Python方法简单一个数量级)。
试探性分析
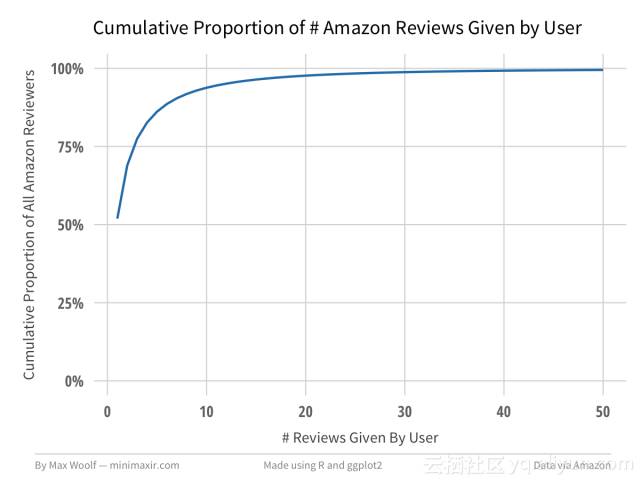
(您可以查看用于Spark处理数据的R代码,并在此R Notebook中生成可视化数据)有20,368,412个有效id的用户在此数据集中提供评论。 其中51.9%的用户只写了一篇评论。
相应地,此数据集中有8,210,439个单独的产品,其中43.3%只有一个评论。
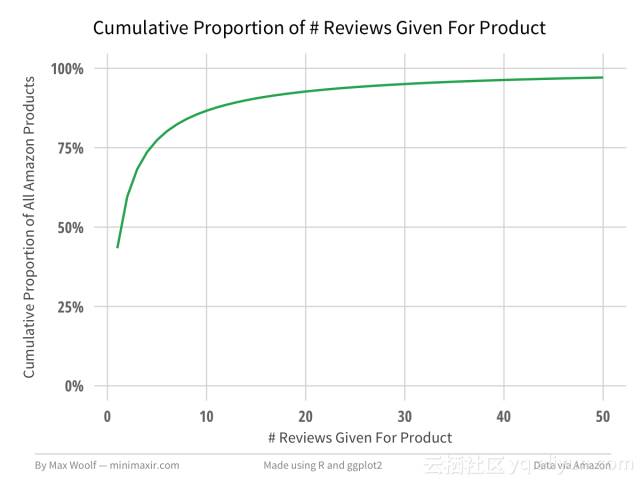
删除几个重复的评分后,我为每个评分添加了几个函数,这可能有助于说明审核行为随时间的变化:一个能表示给定该评论的作者的#评论排名值(作者的第一次评论,第二次评论等),一个指示给定接到该评论的产品已经接收到的#评论(产品的第一评论,产品的第二评论等)的评级值以及进行评论的月份和年份。
前两个添加的函数需要非常大的处理能力,这突出Spark的性能事实上,Spark使用默认情况下所有的CPU核心,而典型的R / Python方法是单线程的!)
这些更改被缓存到Spark DataFrame df_t中。 如果我想确定哪个亚马逊产品类别获得最佳平均评论评分,我可以按类别整合数据,计算每个类别的平均评分,然后排序。多亏Spark的强大功能,这个数百万记录的数据处理需要几秒钟。

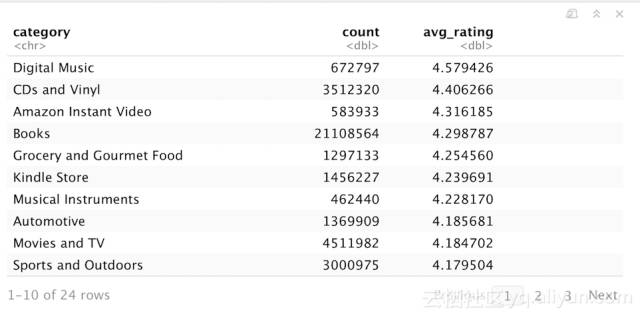
也可以使用ggplot2以图表形式显示:

数字音乐/ CD产品平均获得最高评价,而视频游戏和手机得到最低平均评价,评分范围为0.77。 这确实说明了一些直观的联系; 购买数字音乐和CD这类产品时,你知道你会得到什么,没有产生随机缺陷机会,而手机和配件根据背后的第三方卖家的会有不同的质量(电子游戏尤其容易由于微小的不合理而产生评论的“爆炸”)。
我们可以将每个条细分分成从1-5的每个评级的百分比,更利于该可视化。 也可以将饼图图表划分成不同类别,但像这样码成条形图再缩放到100%能看起来更清爽。
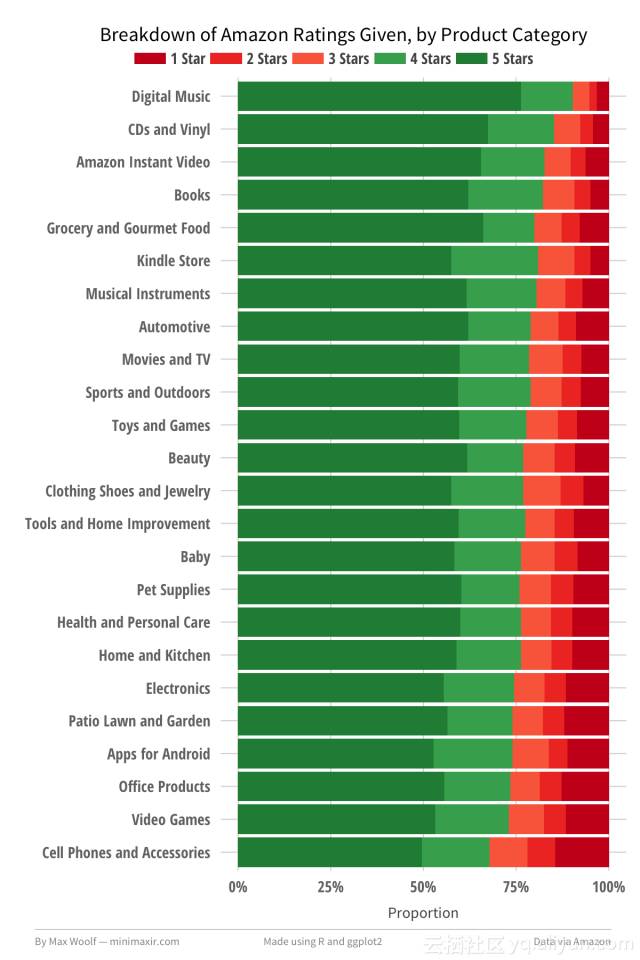
新的图表确实有助于支持上述理论; 顶部的类别的4/5星评级的百分比显著高于底部类别,并且1/2/3星级评分的比例低得多,底部类别与之相反。那么这些故障如何随时间而改变? 还有其他因素在发挥吗?
随时间变化的评级
也许出现在二十世纪二十年代社会媒体中的二元评级“喜欢/不喜欢”已经转化为五星级评论系统的行为。 以下是从2000年1月至2014年7月每月撰写的评论的评分细目:
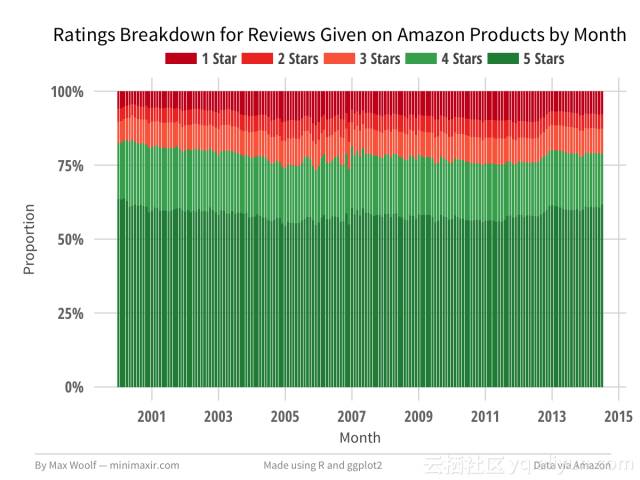
投票行为在一段时间内非常轻微地振荡,没有清晰的尖峰或拐点,这与该理论冲突。
平均值分布
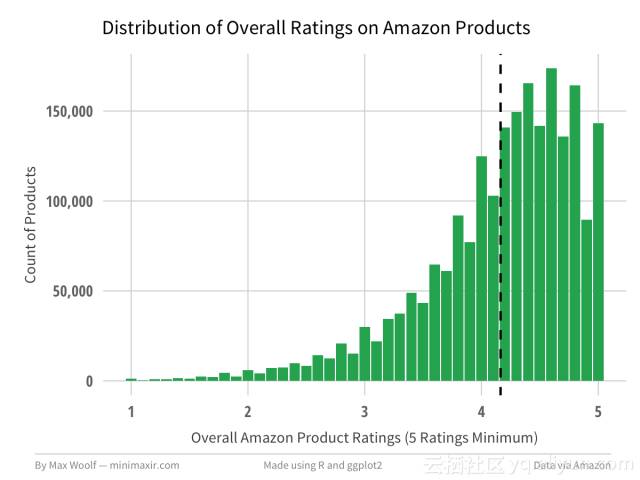
我们应该看看亚马逊的产品分数的全球平均值(即客户在购买产品时看到的),以及给出分级的用户。在我们期望中两者分布匹配,所以任何偏差都会很有趣。关注至少评级5的产品时,有4.16平均总评级:
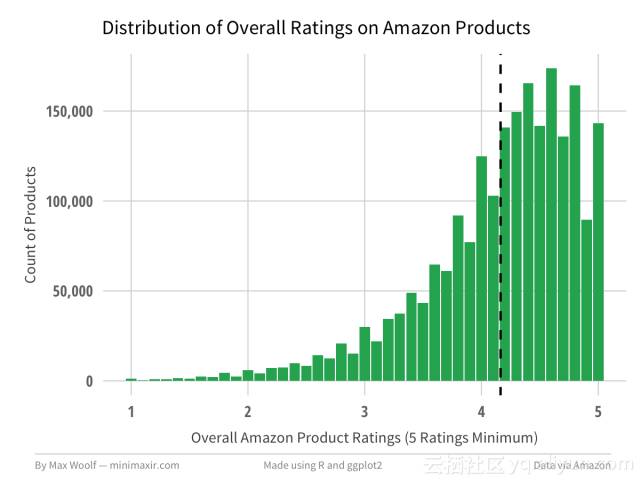
当查看反应用户给出的总体评分类似的图表时(5个评级最低),平均评级略高于4.20。
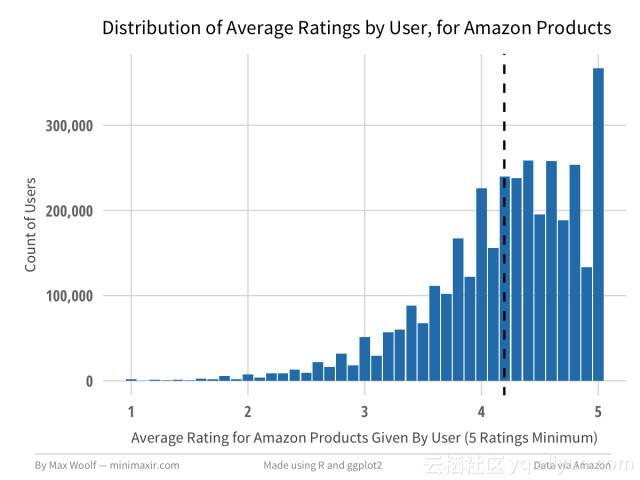
这两种分配的主要区别是亚马逊客户只有5星评价的比例明显更高。归纳和总结两个图表可以清楚突出了差异。
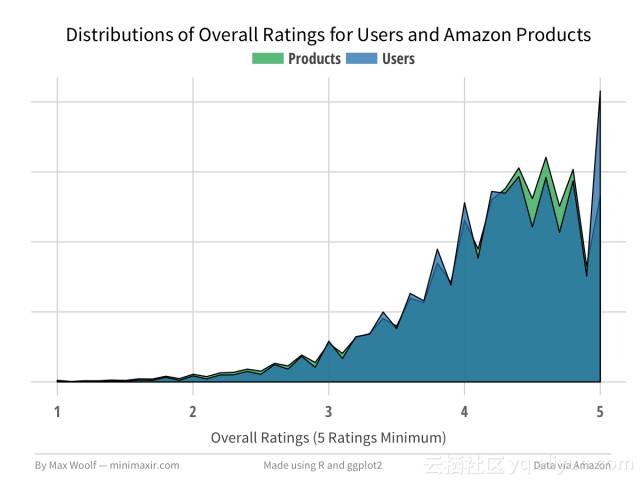
特别的评论
几个帖子前,我讨论了Reddit帖子的第一个评论为何比以后的评论有更大的影响。 在做出越来越多的评论后,用户评分行为是否会改变? 同一件产品的第一次评价,与典型的评级行为是否不同?这里是某个用户给出的几个亚马逊评论的评分细目:
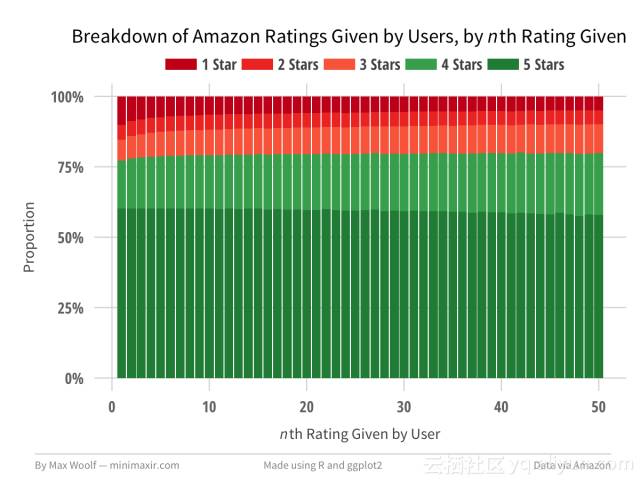
第一个用户评论的评分比之后的评价稍高。其他情况下,评级行为大部分是相同的,虽然用户给4星而不是5星评价的比例增加,由于这样更舒适。相比之下,这里是某亚马逊产品收到的几个评论的评分细目:
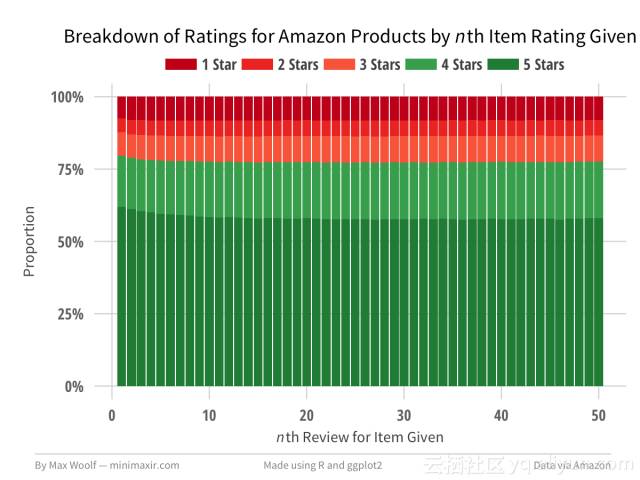
第一个产品评论是5星评价的可能略高于随后的评论。 然而,在第10次审查之后,评级分布没有变化,这意味着特殊评级行为独立于该阈值之后的当前评分。
总结
的确,这篇博文中使用数据多于分析它。 在未来技术发布中,可能更有趣的是特定条件下的行为,例如根据该产品/该用户以前的评价,预测评论的评级。 然而,这篇文章表明,虽然“大数据”可能现在仍是一个令人费解的流行语,但即使你不必为一家财富500强公司工作,也能够理解它。 即使数据集由5个简单的函数组成,您也可以归纳大量的结论。
而这篇文章甚至不需要查看亚马逊的产品评论的文本或与产品相关的元数据! 只要有想法,就能完成。
您可以在R Notebook(http://minimaxir.com/notebooks/amazon-spark/?spm=5176.100239.blogcont69165.12.Eo3vpV)中查看所有用于可视化Amazon数据的R和ggplot2代码。您还可以在此GitHub存储库中查看用于此帖子的镜像/数据(https://github.com/minimaxir/amazon-spark?spm=5176.100239.blogcont69165.13.Eo3vpV)。
原文链接:Playing with 80 Million Amazon Product Review Ratings Using Apache Spark(作者/Max Woolf)http://minimaxir.com/2017/01/amazon-spark/?spm=5176.100239.blogcont69165.14.Eo3vpV&winzoom=1
更多精彩内容参见云栖社区大数据频道https://yq.aliyun.com/big-data;此外,通过Maxcompute及其配套产品,低廉的大数据分析仅需几步,详情访问https://www.aliyun.com/product/odps。
-END-
云栖社区
ID:yunqiinsight
云计算丨互联网架构丨大数据丨机器学习丨运维
博客地址:http://blog.yoqi.me/?p=2736

这篇文章还没有评论