银行拖欠货款用户的特征分析
下面将利用工具SPSS来实现决策树分类。
| 案例:
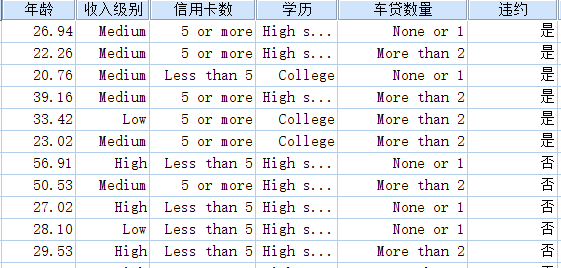
某银行收集了2064个银行货款客户的信息,并且标识出客户是否违约。现在银行想了解一下那些拖欠货款者的客户具体有哪些特征,并且想构建一个模型,用于评估新的货款者的拖欠货款风险的评估。 数据如下所示。
|
IBM SPSS Statistics工具是IBM推出的专业的用于数据分析和数据挖掘的工具,其中内置了大量的数据挖掘模型。决策树模型就在其中,点击菜单:分析à分类à树 打开决策配置界面。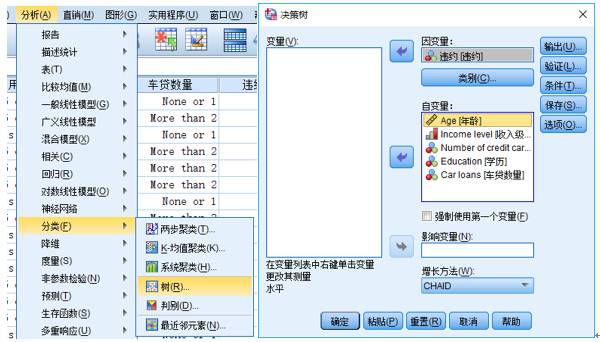
第一步:指定因变量。
将目标变量“违约”选入因变量中,由于“违约”变量可以取两个值“是”或“否”,现在我们要分析“是”这一类客户的特征,所以“类别”中指定目标类,即勾选“是”,然后继续。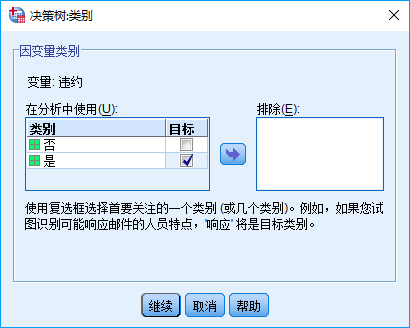
第二步:指定自变量。
将其余所有变量都选入自变量框中,表示要用这些自变量来描述违约客户的特征。
对于预测,一般正常的做法是,先对自变量和因变量进行相关性检验,只有那些对目标变量有显著影响及相关程度高的自变量才会用来预测,需要筛选掉那些没有显著影响的因素。
不过,SPSS在构造决策树时会自动对自变量(因素)进行检验,那些对预测没有显著影响的自变量不会出现在决策树中。因此,你可以将所有自变量都选入自变量框中。
第三步:选择算法。
构造决策树的算法有多种,不同的算法其实现原理稍有区别,详细见上一篇文章。不过SPSS工具中只包含了CHAID,ECHAID,CART和QUEST,并没有包含C5.0。
根据需要,可以选择不同的算法,比如选择默认的CHAID算法。
第四步:配置其余信息。
比如,在“条件”中指定树的最大深度,指定最小个案数。
如果想要评估每个客户违约的概率,可以在“保存”中勾选预测概率。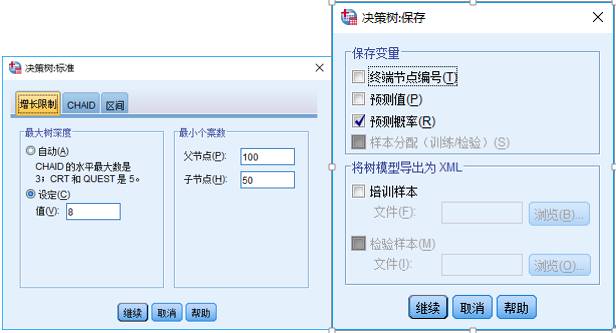
第五步:解读分析结果。
在输出结果中有三个主要内容值得重视:决策树、收益表、混淆矩阵。
首先是决策树,可以看出整个决策树的构成。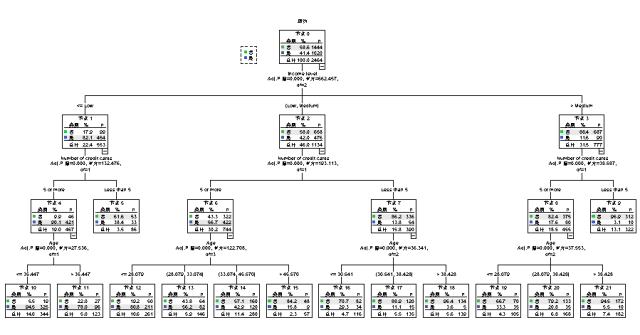
其次是节点的收益表,显示了决策树中每个节点的个案数(N)、增益百分比(节点的查全率)、响应(节点的查准率)、指数(子节点的拖欠比例除以根节点的拖欠比例)。
可以看得出,只有前5个节点的指数大于1,且14节点的指数几乎等于1,只有前4个节点(10~13)值得重视。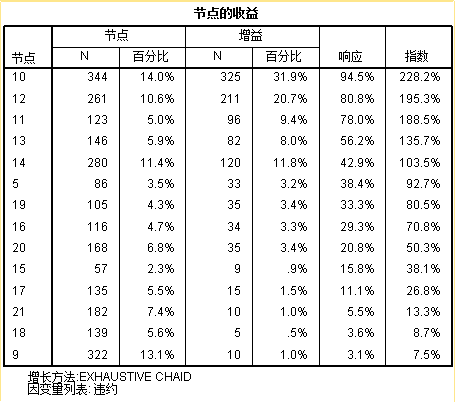
第三是混淆矩阵,评估模型的质量。
如下分类表,即实际的和预测的两类用户数交叉表。其中表中的已观测的所有数据,即是决策树表中所有结点的数据;而已经预测中“是”的这一列数据,只是决策树中前4个节点的数据。
可以计算出模型的查准率为81.1%,而查全率为70.0%。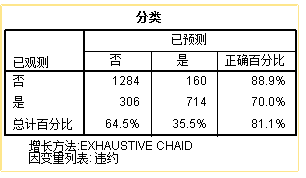
最后,总结拖欠用户特征。
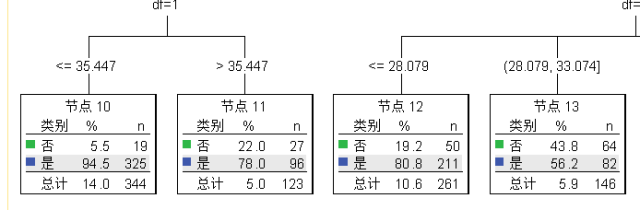
根据前面分析,总结出前4个节点的用户特征:
1) 低收入、信用卡数多(10-11节点);
2) 中收入、信用卡数多且年龄小于33岁(12-13节点)。
第六步:查看单个客户违约的概率。
在原始的表格中,你可以看到单个客户的违约概率。“Predicted Probability_2”就表示违约的概率,如果概率大于0.5则表示预测有可能违约,否则不会违约。
注:此概率值其实就是前面收益表中的响应率(即节点的查准率)。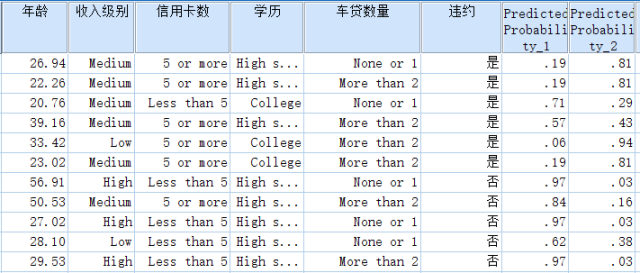
第七步:应用模型
上述模型已经构建好后,即可以应用。当一个新用户来申请货款时,可以应用此模型,将新客户的属性输入模型,看其最后分类位于哪个子节点,并计算其拖欠货款的概率。
拖欠概率越大,表示越有可能拖欠货款。此时,银行将执行风控策略,比如拒绝给新用户货款,或者降低货款的额度。
博客地址:http://blog.yoqi.me/?p=1629
这篇文章还没有评论