【BDTC 2016】专访中兴飞流吕阿斌、郑龙:Yita,基于数据流的大数据计算引擎
【CSDN现场报道】2016年12月8-10日,由中国计算机学会(CCF)主办,CCF大数据专家委员会承办,中国科学院计算技术研究所、中科天玑数据科技股份有限公司与CSDN共同协办,以“聚焦行业最佳实践,数据与应用的深度融合”为主题的2016中国大数据技术大会在北京新云南皇冠假日酒店隆重举办。
在此次大会的大数据分析与生态系统论坛上,中兴飞流信息科技有限公司CTO郑龙发表了“Yita:基于数据流的大数据计算引擎”的演讲,阐述了数据流对于大数据的影响,以及中兴飞流自主研发的Yita平台能够给大数据产业带来的价值,在会议的间隙,CSDN记者有幸对中兴飞流信息科技有限公司CEO吕阿斌、CTO郑龙就数据流技术以及中兴飞流的Yita平台进行了深入的交流和探讨。
什么是数据流?
中兴飞流CEO吕阿斌首先就数据流模型产生的背景进行了阐述,他表示,近年来,大数据成为继云计算以后一个重要的科技发展分支。大数据本质上是研究如何利用好数据的问题,而数据才是最重要的资产,因此,大数据比云计算更具有现实应用的意义,它可能发生在社会生产生活中更重要的一方面。大数据的发展有一个历程,早期数据的产生、存储、计算依赖于数据库,但当时数据量不大,数据计算过程相对来说比较规范,尤其是数据格式相对来说比较标准,所以数据库基本能够解决大多数的事情,例如,基于数据库的数据挖掘、分析等等。但更复杂的数据分析是和数学结合在一起的,而复杂的数学模型在其中起到了重要的作用,但因为没有和具体应用结合,因而并没有完全发挥出数学模型的作用。
随着网络、移动互联网的飞速发展,数据的形式越来越多,从以单一的结构化数据为主发展成为由文本、图片、文件等多种形式组成的非结构化数据为主,同时,数据的数量也呈现出指数级的增长,在这样的情况下,只有通过高效的算法和有效数据的具体结合,才能从海量的数据中挖掘真正的信息价值,而实际上,这就是所谓的数据智能,也是未来大数据真正的发展方向。
吕阿斌继续解释道,数据智能说的再高一点就是人工智能,人工智能最重要的就是应用、算法、计算平台和数据,对于数据智能同样如此,但要建立高效的数据智能的计算平台,首先需要了解大数据时代数据处理的特点:
第一个特点是海量实时处理。在以前,很多数据都是事后处理,而在大数据时代,海量实时处理的需求非常普遍,比如在交通领域的视频分析中,对于人流、车流、异物等情况的分析要快速得出结果,不能事后再记。再比如在金融领域的投资分析,因为国内国际政治经济形势瞬息万变,因此如果没有快速实时的分析结果,投资的效果可能就是相反的。这就是海量数据下的实时处理需求。
第二个特点是智能。以前对数据只是做简单的处理,分类,聚合,而在大数据时代,需要对数据进行复杂计算,需要高效的算法,比如分类算法、聚类算法、深度学习、神经网络等来对数据进行深度的分析,得出有价值的信息,这就是对智能的要求。而高效的算法需要运行在一个计算框架里面,这个框架就是计算平台。但算法再好,如果计算处理平台不行的话,就无法满足大数据时代智能的需求。
而海量实时计算和智能对计算平台有着更高的要求,但依靠传统的冯∙诺依曼模型控制理论,实际上很难高效满足大数据时代的这两个需求。因此,在这种情况下,更适应大数据时代需求的数据流模型脱颖而出。而实际上,数据流的概念在70年代就有,由MIT杰克∙丹尼斯教授和中兴飞流顾问高光荣教授研发,但由于当时控制流的技术得到了主流硬件和操作系统厂商,如英特尔,微软的支持,因此,数据流模型并没有被业界所重视。
但当大数据出现以后,数据流计算模型在并行计算上的特点,能够较好的满足大数据时代数据处理的两个需求。在控制流模型中,通过等同步的方式进行计算,计算需要等待上一步计算结束,才能进行下一步计算(如图1所示),在等待同步的过程中,计算资源是被白白浪费的,而流式计算则可以同时进行其他计算,因此,数据流计算特别适合于有海量实时需求的大数据处理领域。
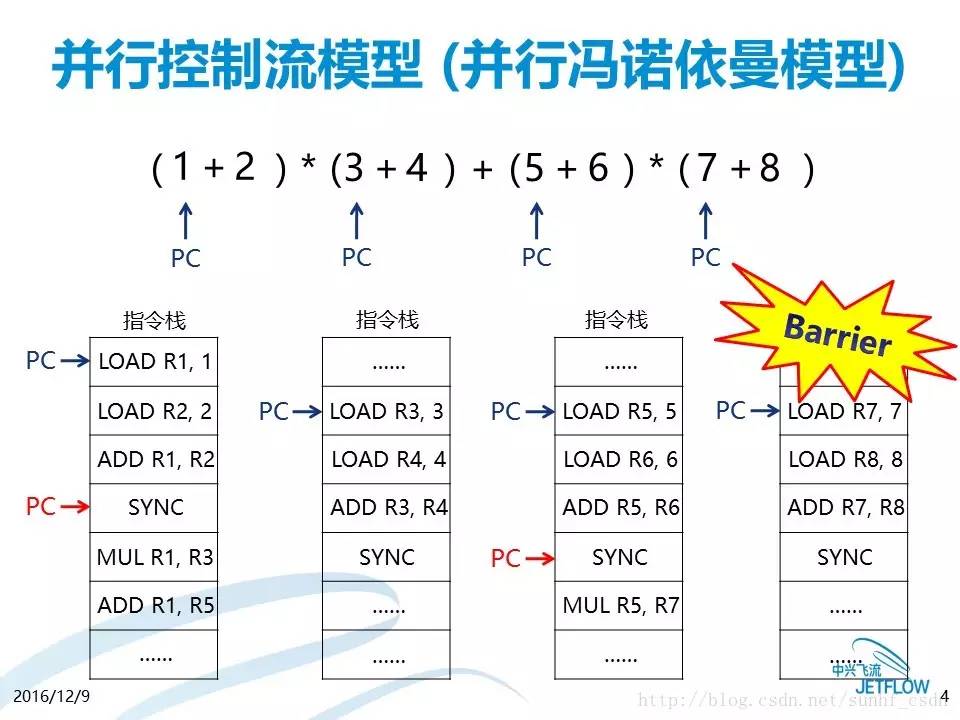
图1 例如,当需要计算如图中(A+B)*C的算式时,传统的控制流方式需要等待A,B,C三者都被赋值后才能开始计算,而采用数据流模型,只要A,B两者被赋值即可开始计算
简单来说,数据流和控制流的最主要区别和特征就是细颗粒度的异步计算,而无需等待全局的同步,数据流的这个特征非常适合大数据的处理,在计算的过程中不会有太多的衰减,尤其是在海量实时处理时更具有优势。
中兴飞流CTO郑龙也对数据流模型进行了补充解释,他表示,控制流模型有点像以前的计划经济,计算的每个步骤都是预先设定好的,这在以前的静态数据处理时,没有问题,但在当前的大数据处理过程中,数据是变化的、动态的,一旦在计算的过程中数据出现了变化,就会给下一步计算造成很大的麻烦。而数据流模型更加像市场经济,它只是制定一定的规则,只要有数据、计算资源,就可以进行处理,当数据出现变化时,会动态的增加或者减少资源来应对数据的变化,这种高效的资源调度模式可以最大限度的利用资源,这是数据流在处理海量数据时延时低的主要原因。
Yita,数据流大数据计算引擎
正是看到了数据流模型在大数据处理方面的优势,中兴飞流推出了基于数据流模型的Yita大数据计算引擎。在谈到中兴飞流研发Yita的背景时,郑龙表示,现有的Spark、Storm等大数据平台主要使得原来海量数据从无法计算、无法有效时间内计算变成了有办法计算,但在实际应用当中会遇到很多问题,比如计算效率过慢,对数据量的支持不高,对算法的支持度不够等等。而Yita的研发背景就是要进一步增强海量数据的计算效率,实现海量、实时、智能的大数据处理。而传统的基于同步计算模式的Spark、Storm平台受制于控制流模型的局限,已经逐渐不太适合当今的大数据处理。
郑龙表示,大数据的特点是高维稀疏,所谓高维就是数据量多,数据维度多,数据种类多,例如,对上网用户进行精准画像时,用户的信息、用户的上网行为、用户使用的APP、用户的网站喜好、用户的浏览习惯等都是可以采集的数据。所谓稀疏是指数据是分散的,同样的精准画像的例子,例如,有个用户用了一个非常冷门的APP,这个APP只有千分之一或者万分之一的人在用,这就是稀疏。
而要根据大数据的这两个特点进行大数据分析,实际上对实时计算是一个很大的挑战,其中要涉及智能计算、数据汇总、算法模型、资源调度等等很多方面的技术。
而基于数据流理论的Yita正是有效解决这些问题的大数据平台,它具有两大优势:
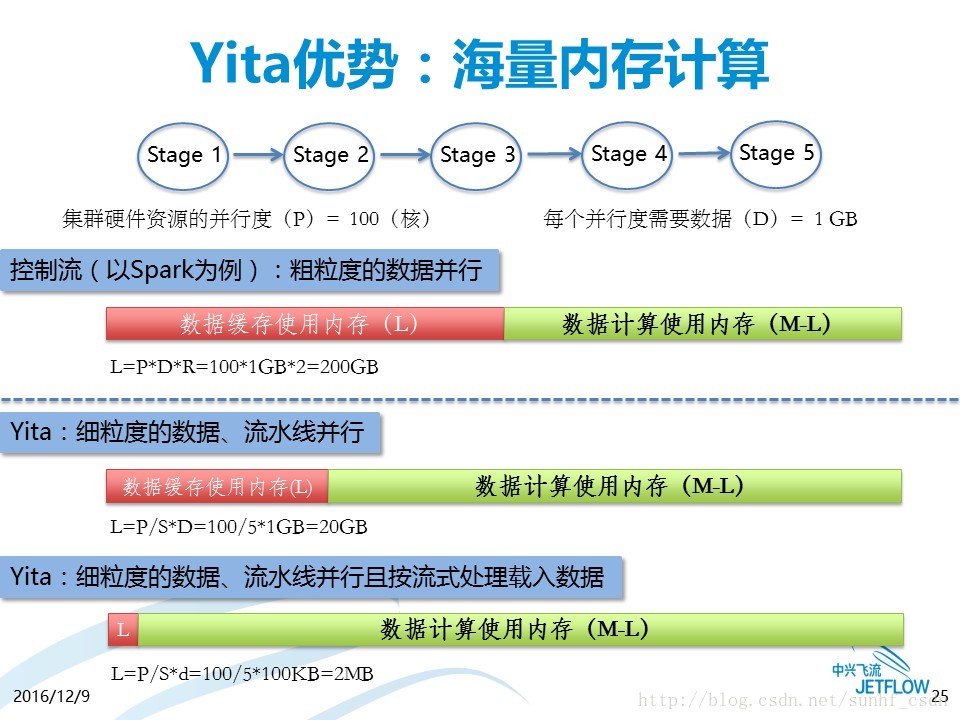
其一是海量内存计算,采用控制流模型的计算方法是把数据的一部分先放进内存,然后开始计算,这样内存就同时要处理两项工作,一项是数据的缓存,一项是数据的计算,但实际上决定计算能力的是除去负担缓存工作之外的内存容量,而很多计算效率不高,是因为数据缓存占的多,留给计算的内存少,这就是现在内存计算领域遇到的很大问题。而数据流可以很好的解决这个问题,数据流的基本思想不是载入、然后计算、然后输出的模式,它是一边载入一边计算一边输出的模式,所以不需要预载入那么多数据,而是像流水一样一点点的不断载入,这种计算方式,在数据载入方面耗费的内存量非常低,大量内存被留给了数据计算,因而能够更加高效的利用内存,这也就是为什么在同样内存量的条件下,Yita能够支撑比Spark更多的计算的原因。
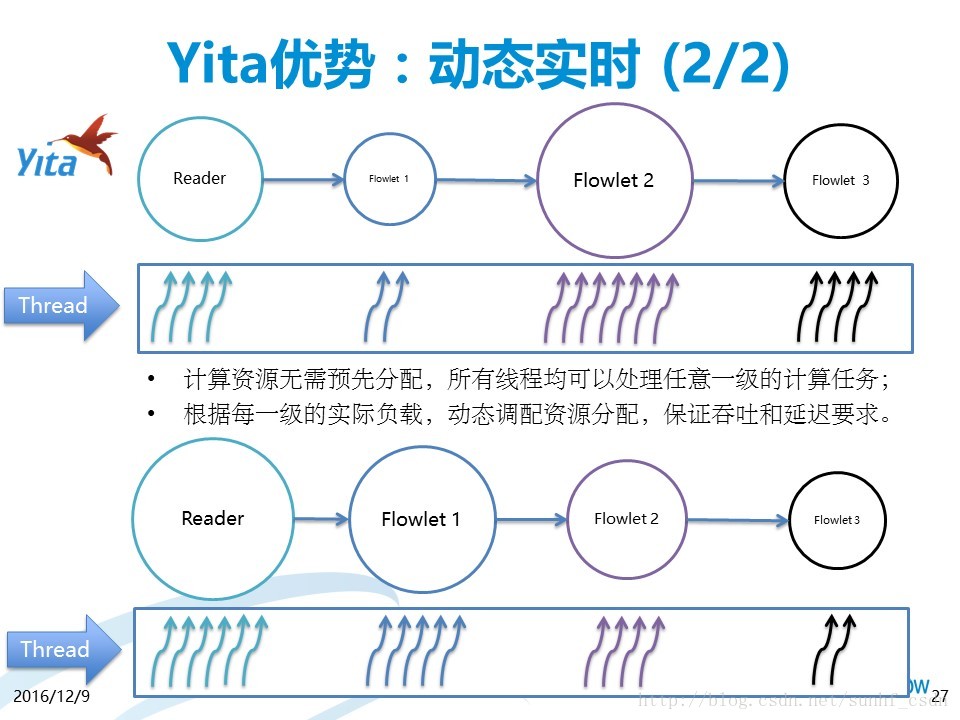
其二是动态实时,我们会发现当内存的使用量接近临界值的时候,计算会变很慢,这主要因为C、Java等语言的内存设计机制导致的,计算如果超过内存量计算将会不成功,同时内存用的过多还有可能造成计算能力大幅下降,而数据流可以根据每一级的实际负载,动态调配资源分配,保证吞吐和延迟要求。这使得Yita的计算可以一直保持高效,并且在接近系统瓶颈的时候计算性能依然保持是线性的,因此可以提供相对于传统控制流大数据平台10多倍的性能。
中兴飞流,做中国大数据核心技术的探索者
在采访的最后,吕阿斌对中兴飞流进行了简单的介绍,他表示,大数据发展的未来趋势就是数据智能,怎么把数据变成智能化的应用,不仅需要好的技术,好的商业运作公司,更需要有立足自身的核心技术,而脱胎于中兴通讯的中兴飞流就是这样一家以技术为核心的公司,中兴飞流主要聚焦于下一代大数据处理平台、算法以及在一些关键垂直领域的应用。
郑龙补充道:“中国在系统软件领域没有自己的核心技术,真正的核心竞争力都在国外,而大数据给了中国企业一个机会,但在以Hadoop为代表的第一代大数据浪潮中,我们错过了,第二代以Spark、Storm这种内存计算、实时计算为雏形的时候我们也错过了,而在以海量、智能、实时为标志的第三代大数据技术浪潮中,中兴飞流希望做一次努力的尝试,希望在大数据海量、实时、智能的技术演进中至少为中国自有技术在大数据领域中贡献一次创新,虽然Yita不一定最终能成为整个大数据生态系统中的全部,但至少我们在这里面贡献了一个很重要的,很有意义的一个模块、一个组件。我们在Yita上面有一些自己独到的应用,有一些非常擅长的领域,这能够让中国的技术第一次站在大数据技术的前沿,能够掌握自己的核心竞争力,不再被别人牵着鼻子走,这是从技术人角度更大的愿景,我们也考虑把Yita开源、把Yita贡献成为整个中国的财富甚至世界的财富,这是我们在技术上的理想和愿景,是我们的诗和远方!”
博客地址:http://blog.yoqi.me/?p=1333
这篇文章还没有评论