两分钟demo:自动驾驶入门之别撞人和公共汽车了
本文经作者授权转载,转自知乎专栏《两分钟深度学习demo》。
这次的两分钟深度学习demo要讲的是卷积网络的另一个应用,通过视觉和深度神经网络实时检测目标。它是
,毕竟除了让车“按着线开”这样的相对简单的任务,也得让车认识周围环境这样才不会引发交通事故。计时开始。
Demo 演示
系统要求:和 FlappyBird 的demo一样,要求 python,MXNet,X11,有支持CUDA的nVidia GPU。这个 Demo 仍然专注使用 MXNet 作为深度学习平台运行,请按照安装说明自行安装编译GPU版的MXNet并在config.mk里打开 cuDNN支持,github 传送门 https://github.com/dmlc/mxnet
SSD单网络多目标检测github传送门 zhreshold/mxnet-ssd 感谢 Joshua Z. Zhang 老师细致完备的工作,让我们可以快速上手学习。在 git clone 之后,我们需要下载预先训练好的模型 ssd_300_voc_0712.zip,放到 models/ 目录里并解压缩。然后到这里下载我们旧金山市街头一张街景图当作输入并执行:

python demo.py --images sf_street.jpg Detection time for 1 images: 0.3850 sec
可以看到,一块 GTX 960的运算能力可以在0.385秒内识别出图中的公共汽车和近景的行人,并且连图片右下角出现半个的人都可以识别并精确圈出位置。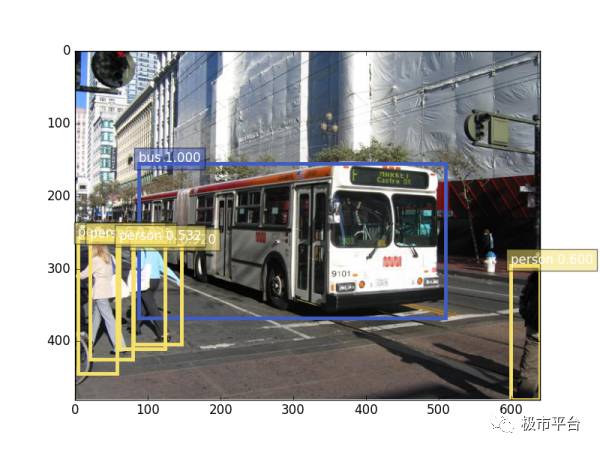
另外一个例子也是旧金山街景,程序在很短的时间里识别出了近处路面上的汽车,包括各种朝向和停在路边的各种汽车(输入图片下载地址):
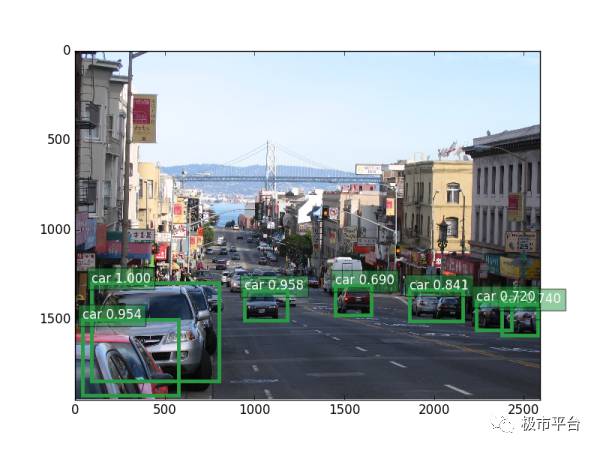
注意:如果之前没有安装 matplotlib 这个软件包,请使用 pip install matplotlib 安装。
技术要点:这个demo需要重新编译安装一下自带的mxnet fork repo,里面包含作者自己实现的“mx.symbol.Scale”,否则会出现这个错误:
from_layer = mx.symbol.Scale(data=from_layer, mode="spatial", AttributeError: 'module' object has no attribute 'Scale'
理论知识
物体检测是计算机视觉里基础研究课题之一,它的任务是在一张图里找到想要的物体以及对应的位置。在最近的自动驾驶汽车热潮里,它更有自己不可替代的地位,需要不断追求更快更准确更容错的检测方法。基于深度神经网络的常见方法一般是 Faster RCNN(MXNet实现 github 传送门 precedenceguo/mx-rcnn ),Yolo (You Only Look Once),SSD等,这里有一个总结大全,感兴趣的观众朋友可以参考 Object Detection 。
传统目标检测方法一般通过扫描整个图片(selective search)寻找可能是物体的区域并画个大概的框,然后通过一个卷积网络判断这个区域里是不是物体以及是哪种物体,再优化这个框的位置。在 Faster RCCN里,它通过一个卷积网络 RPN (Region Proposal Network) 快速画这个大框。它的方法是把RPN的最后一层卷积层输出的特征(feature map)的点对应到原图的一群点,用这些点周围的区域(称之为锚点 anchors)来训练 RPN,对于每一个锚点区域如果它和图片中某个物体重叠部分小于某个阈值就被认为是背景,而背景的损失函数值设定为0,以此优化和训练 RPN 使之学习到相对精确的物体位置。
SSD: Single Shot MultiBox Detector 这个2015年提出的方法使用单个网络实现同一张图里多个行人、汽车等目标的识别,它对比其他方法的优势在于实时和快速,这个demo的实验可以达到每秒95张图(单张Titan X)的速度。它同时也解决了 Faster RCNN从最后一层卷积层回推导致原图里太小的物体不能识别的问题,它允许每一卷积层德特征点都可以回推到原图寻找锚点,从而可以识别出来相对更小的目标。
随着物体检测不断发展,现有算法的弱点比如说检测过小的目标,各种光照条件下的物体检测等问题都会不断的克服,未来会有越来越多的有效检测方法。
思考题
- 为什么自动驾驶汽车需要快速准确的物体检测方法?
- RPN的方法对传统方法有什么优势?这些优势是怎么在深度网络里体现的?
- 在 Joshua Z. Zhang 老师的代码里,定义了哪几种可以识别和检测的物体?参考答案看 demo.py 的开头部分。
- 这一套代码速度很快,可以用到视频的实时识别上,你有兴趣写一个视频识别版么?在评论里留下 github 链接,我会替你点赞的。
加分题
这个demo使用了默认参数,观众朋友们可能发现有些近景的单人被标记了多次,远景的部分汽车没有很好的识别到。它可以通过调整哪些参数进一步优化,这个任务就当作加分题留给观众朋友们在代码里摸索。
两分钟阅读时间结束。这是后记。物体目标检测是一个比较难但是比较贴近实际生活的话题,它让观众朋友们接触一下自动驾驶汽车里面需要的深度学习技术。我也想通过介绍冰山一角体验一下技术难度,毕竟我们不能像某些培训班那样开个收费培训教跑个“按着线开”的demo然后就告诉你自动驾驶就这么简单你明天就可以自己做个车上路啦,这样多危险啊。在国内外很多公司在探索研究和制作各种自动驾驶汽车,国内做的比较好的比如说图森互联基于视觉的自动驾驶,他们主要成员也是MXNet的重要贡献者。如果有兴趣接受自动驾驶的科研挑战,不妨考虑和这些优秀的研究组学习合作,参加一线科研工作,共同推进自动驾驶汽车的发展。
当然了,搞深度学习还是要用最好用的平台 MXNet。
博客地址:http://blog.yoqi.me/?p=1626
这篇文章还没有评论