对监控系统的一些思考
2011年、2012年我在PPTV刚开始工作的时候,第一个开始涉及的工作就是监控系统。当时和我的老板陈文春(现在应该是新浪的总经理吧,好厉害)一起在Nagios和Zabbix中选型,当时觉得Nagios有各种各样的插件,功能很强大,但相应地配置麻烦,比如画图需要cacti配合。而Zabbix看上去是一个一步到位能解决所有问题的工具,虽然界面有点丑,但能满足我们的需求:画图、报警收集数据等。近年来的发展趋势,Zabbix比Nagios更加流行,我看了下Google Trends,Nagios的热度在缓慢下降,而Zabbix的热度在上升:
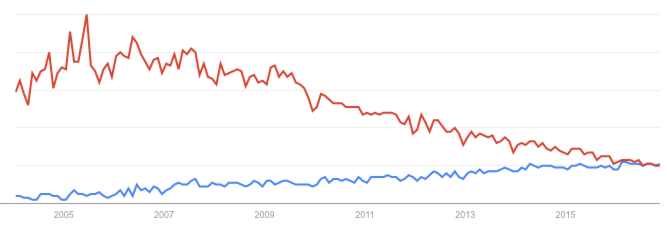
在Zabbix所监控的服务器越来越多情况下,对Zabbix的性能要求也越来越高。因为团队中大家对Oracle有更多的了解,我们Zabbix后端使用的数据库也是Oracle,这个应该是比较少见的,因为我了解下来目前肯定是MySQL更加流行(其实PPTV后来也换成了MySQL)。
在当时Zabbix功能还不是非常强大,有很多需求没法满足。这种情况下我们围绕Zabbix做了很多的工作:
-
开发了添加监控时使用的工具Spider,原理很简单:根据不同的规则,在将一台服务器添加到Zabbix监控时,会根据服务器上运行的进程,或者hostname(PPTV的hostname中有服务器所属业务的信息)来添加对应的监控;
-
重新开发了Zabbix的Screen功能,支持更加方便组合需要的监控数据,因为Zabbix自带的Screen功能配置比较麻烦;
-
当出现报警的时候,Zabbix只负责将报警的信息推送出来,由我们自己开发的工具,根据Zabbix的信息,重新组合报警信息,将这一报警事件展现到报警平台中,并且将更加详细的报警邮件发送到CMDB中对应的负责人那。这样可以做到每一个报警事件的认领,追踪和解决。对于一些报警,邮件中能有初步的分析,工程师收到邮件就能大概知道问题发生的地方;
-
从代码入手,解决了Zabbix在Oracle中执行SQL的一些性能问题;
-
使用Nagios监控Zabbix Master和Proxy的Update Percent,这个指的意义是过去一段时间内,有百分之多少的数据更新了。这个数据能很好地反应Master和Proxy的健康程度。
总结一下,我们在这几方面做了开发:
-
更全面的收集监控数据;
-
更好的展现监控数据;
-
梳理了报警的流程和操作;
-
优化后端数据存储的性能问题(主要是写的性能);
-
提高Zabbix的可用性。
➤现状
在离开PPTV加入唯品会后,我基本没有很深入地去做Zabbix工作,除了做了一个Zabbix Lastvalue的patch。简单介绍下这个Patch,Zabbix对于每一个监控项,会在一张表中保存这个监控项最近一次的取值,有了这个指标,可以方便做一些二次开发。而在Zabbix 2.2(印象中是这个版本),这一列取消了,而我做的Lastvalue的patch,就是让Zabbix在将监控数据写入数据库的同时,再写一份到一张新的表,而这张表,就是原来Lastvalue的功能,这里要特别感谢唯品会的聂超和侯瑞,解决了C的内存泄露问题。
一直到现在,五年间,有很多身边的同事,或者网络上的朋友在做监控系统的开发,而我也在关注监控系统的发展。我发现,对于监控系统,大家可能有一些错误的认识,有的同学自己写了一个收集系统数据的工具,然后数据往后端发送,再做一些数据可视化的工作,这也是“监控系统”。对于这些造轮子的行为,这里不做具体的评价,因为它们确实能解决一些问题,但总的来说,和Zabbix(或者其他监控系统)的区别是不大的,自己重新开发一套没有什么必要。而且,Zabbix是这么多年时间、这么多优秀工程师一起努力的结果,不是这么容易就能开发一套比Zabbix做的更好的产品。我甚至见过,所有思想全部抄袭Zabbix,比如Dashboard的设计:报警的级别、触发器表达式的格式,和Zabbix几乎一致,老板甚至还觉得不错。
Zabbix或者类似的开源产品存在着很多问题,我列举一下:
-
使用TSDB或者NoSQL来解决监控数据的存储问题;
-
将大数据的解决方案引入监控系统,增强监控系统的可扩展性,比如Storm,Spark,Kafka等;
-
使用机器学习来改进报警准确性的问题,比如触发报警的条件,报警事件的聚合等;
-
将前端界面开发得更漂亮一点。
可以看到,上面4点,最简单的就是第4点了,所以有很多工程师在这个上面做文章,我个人认为,目前监控系统的最大问题是第1点——数据的存储问题。监控数据的量会非常大,假设我们有10k台服务器,每个机器有50个监控点,那最坏的情况,需要每秒处理500k个请求。如果不做任何优化,500k每秒的写入压力,就算对于大数据的实时计算,也是很大的压力。另一方面,监控数据的读取也很有特点,经常会读取很长一段时间的数据,比如我想查看一个监控数据在过去一个月的数据,那映射到数据存储层,会需要扫描非常多的数据。可能从后端返回的数据量会非常大。
由于数据库的性能不佳,可能会造成部署多套监控系统的情况,这样在读取数据、做聚合分析时有很大的难度。当然,也可以在多个数据库的上层开发一个统一的API,这就有点像TDDL了,难度很大。
对于第2点和第3点,如果我们能解决第1点,并且我们已经习惯了目前监控系统处理监控数据的架构以及报警方式,我觉得这两点给我们带来的痛点还在可接受范围内。而对于第4点,虽然说数据可视化是数据处理整个流程中非常重要的一环,但它的重要性远不及上面几点。
➤怎么造轮子
用开源产品做二次开发?还是自己造轮子?我觉得需要根据具体的需求,但可以确定的是,当你决定自己造轮子时,80%的情况下,开源产品是能满足你的需求的。记得有句话是讲NoSQL的,大意是:当你想要NoSQL的时候,80%的情况下MySQL就能解决你的问题。
我觉得只有在我们已经非常了解一个开源产品并且用透了(半年以上)的情况下,如果确实不满足我们的需求,那么可以对其他类似产品,和其他公司的解决方案进行调研,看看大家的解决方案,因为很有可能我们并不是第一个想造轮子的人(如果你是第一个想造轮子的则需要更加谨慎,想想为什么其他人都不造轮子呢?)。
如果已经决定造轮子了(再次提醒各位,80%的情况下你是不必造轮子的),那要搞清楚造轮子的方向,不要只把原有产品的一个小部分非关键组件自己开发了就是造轮子,然后就沾沾自喜,认为自己把轮子造完了。
回到这篇文章想和大家聊的监控系统,我在前文说过,监控系统目前的问题,有几个:
-
监控数据这种时间序列数据的存储;
-
报警的优化,包括报警准确性和报警的关联;
-
监控系统的可扩展性,要支持监控点增多后的水平扩展。
下面我们分别从这三个部分来做些简单的介绍。
时间序列数据
传统的监控系统会将监控数据存储到传统的RDBMS,比如最常见的MySQL。我们先等会说这个做法是否合适,先看看时间序列数据是怎样的。时间序列数据(Time Series Data)是一系列以时间序列为顺序的数据。比如监控系统中,一段时间内某一台服务器的CPU Load的值,是一个时间序列数据。这个时间序列数据中,包含几个隐含的条件:“某一台”,“CPU Load”,“值”,还有就是时间。所以可以这么说,“某一台”服务器的“CPU Load”这个数据在某一个时间的“值”是XX。我们更加抽象一点:
TIMESTAMP, METRICS, TAGS={K1: V1, K2,: V2,…}, FIELDS={F1: V1, F2: V2,…}
时间序列数据有个特点,TAGS和FIELDS里面有多少个Key-Value是不能确定的。也就是说数据的Schema是不确定的,那么我们用MySQL去存储时间序列数据是否合适呢?我们都知道MySQL任何一张表都需要事先去定义表结构。
我们得出一个结论,传统的RDBMS不是存储时间序列数据的,我们需要专门的时间序列数据库——Time Series DataBase,即TSDB。
目前比较流行的有基于HBase的OpenTSDB。HBase的存储方式是列式的,这个特性对时间序列数据的读取很有好处,因为相同Metrics一段时间内的数据在磁盘上都存储在一起,读取性能会很好。但在使用过程中会发现:当TAG数目比较多时,性能会非常差,而且整个HBase的搭建和维护比较麻烦。
当前更加流行的开源产品有InfluxDB,Prometheus和Netflix的atlas,未开源产品有Twitter的Manhattan。我们现在主要使用InfluxDB,它是用Golang写的,根据官方的benchmark,读写性能和数据压缩都大幅领先当前的产品。并且它支持类似SQL语法的数据查询语言,使用起来非常方便。
机器学习的引入
监控系统的最大价值就是将故障准确地通知出来,但现实情况中却有非常多的误报以及频繁的调节阈值。关于使用机器学习来调整阈值的研究,已经在上一期《程序员》中做了简单的分享,最核心的思想就是根据数据的历史,来做一些未来数据的预测。
另一方面,报警事件的关联其实也是非常有趣的事情,比如一台服务器上面的磁盘空间满了,同时,这台服务器上运行的MySQL也失去响应了,这两个报警,是不是可以认为是一个相互关联的事件呢?这方面我的研究不多,但这个问题是确实存在的。我的想法是,系统在初始情况下,所有的报警事件是没有关联的,经过一些“专家”的训练(比如将两件报警事件人为的关联),当下次这两个报警事件再同时出现时,系统就会提示这些关联的关系。
监控系统的分布式架构
监控系统在发展过程中都非常喜欢将所有的时间放在自己这,比如数据的传输、计算之类。例如Zabbix就自己实现了数据的队列、缓存以及数据是否需要报警的逻辑处理,其实这些如果能交给大数据组件来解决,应该是更好的选择。当规模足够大以后,监控系统所面对的场景就是大数据的场景——海量数据的传输、计算和存储。专业的事情交给专业的平台来做,这样更合适。
结合上面三点,我认为,监控系统应该专注在如何让监控更准确、更智能,而数据的计算、传输等用大数据的工具来解决。这样,监控系统会有更强大的生命力。
作者:姚仁捷,游族网络运维开发经理,负责运维数据方面的工作,希望能结合大数据和机器学习,帮助数据化运维体系的建设。之前曾经在唯品会,PPTV和eBay工作,主要负责实时计算和监控系统相关。
责编:郭芮,关注大数据领域,寻求报道或者投稿请发邮件guorui@csdn.net。另有「CSDN Spark用户群」,欢迎加微信guorui_1118申请入群,备注姓名+公司+职位。
130+位讲师,16大分论坛,中国科学院院士陈润生,美国伊利诺伊大学香槟分校(UIUC)计算机系教授翟成祥,驭势科技联合创始人、CEO吴甘沙,上交所前总工程师白硕等专家将亲临2016中国大数据技术大会,预购从速。
博客地址:http://blog.yoqi.me/?p=1228
这篇文章还没有评论